
[논문] SRGAN: Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network
업데이트:
최초로 deep learning을 super resolution에 적용한 SRCNN 이후 더 빠르고, 더 깊은 CNN 모델들이 제시되었음에도 불구하고, 이 논문은 여전히 해결되지 않은 문제점이 있다 제시합니다.
How do we recover the finer texture details when we super-resolve at large upscaling factors?
최적화를 기반으로 하는 super resolution method는 objective function의 설정에 따라서 그 성능이 바뀌었으며, 특히 mean squared reconstruction error를 최소화하는데에 집중되어 있었습니다. 이런 경향은 결국 높은 PSNR 값을 주었지만, 사람이 보기에는 만족스럽지 못한 결과물들을 제시하였습니다. 이 논문은 SRGAN이라는 새로운 모델을 제시하여 이러한 문제점을 해결하고자 합니다. 이 방법은 최초로 4배 upscaling하는 것을 가능하게 하였으며, 이를 위해 adversarial loss와 content loss를 모두 포함하고 있는 perceptual loss function을 제시하였습니다. 추가적으로 content loss는 픽셀 공간 사이의 유사성이 아닌 인지적 유사성을 담고 있습니다.
1. Introduction

Low Resolution(저화질)의 이미지를 High Resolution(고화질)으로 바꾸는 것을 super resolution(SR)이라 합니다. 이 SR에서의 문제점은 super resolution을 통해 고화질의 이미지가 만들어졌을때, texture의 detail이 부족하다는 점입니다. SR 알고리즘들의 목표는 보통 복구된 HR 이미지와 원본 이미지 사이의 MSE를 최소화 하는 것인데, 이는 이미지의 품질을 평가하는 PSNR의 값을 향상시키는 효과가 있습니다. 하지만, 이 MSE와 PSNR은 pixel-wise 이미지 차이로 정의되어 있기 때문에 high texture detail과 같은 지각적인 부분과 관련있는 차이점에 대해서는 그 능력이 한정되어 있습니다. 그래서 이 논문에서는 skip-connection이 있는 ResNet을 이용하고 MSE만을 최적화의 수단으로 이용하는것에서 벗어난 super-resolution generative adversarial network(SRGAN)을 제시합니다. 이전 연구와는 다르게 VGG network의 high-level feature map을 이용한 독보적인 perceptual loss를 제시하고 이를 기반으로 만들어진 figure 1과 같은 4배 upscale된 예시를 보여줍니다.

Figure2는 각각의 upscale들의 성능을 보여주며, SRResNet의 이미지를 보면 실제로 SRGAN과 비교했을때 디테일한 부분들에 대해서 완성도가 부족함을 볼 수 있습니다.
Mean Square Error (MSE)
\[MSE = {1 \over XY} \sum_{x=0}^{X-1} \sum_{y=0}^{Y-1} e\left(x, y \right)^2\]여러 super resolution method들은 MSE를 loss function으로 이용합니다. 이는 원본 이미지와 super resolution을 통해서 생성된 high resolution 이미지 사이의 차이를 측정하는 수단이며 PSNR을 계산하는데에 MSE가 사용됩니다.
Peak Signal-to-Noise Ratio (PSNR)
\[PSNR = 10 \log {s^2 \over MSE}\]PSNR은 이미지 품질을 평가하는데에 사용되는 수단으로 super resolution 뿐만 아니라 다른 여러 분야에서도 이용되는 방법입니다. 이 PNSR은 신호가 가질수 있는 최대 전력에 대한 잡음의 전력을 나타낸 것입니다. 주로 영상 또는 이미지 손실 압축에서 화질 손실 정보를 평가할 때 사용되며 MSE를 이용해서 계산할 수 있습니다. \(s\)는 영상에서의 최대 값으로 해당 채널의 최대값에서 최솟값을 뺀 값입니다. 예를 들어 8bit grayscale의 영상의 경우에는 \(255 - 0\)이기 때문에 \(255\)가 됩니다. 로그 스케일에서 측정하기 때문에 손실이 적을수록 더 높은 값을 갖게 됩니다. 손실이 없는 경우에는 MSE가 \(0\)이므로 PSNR은 정의되지 않습니다.
Loss Functions
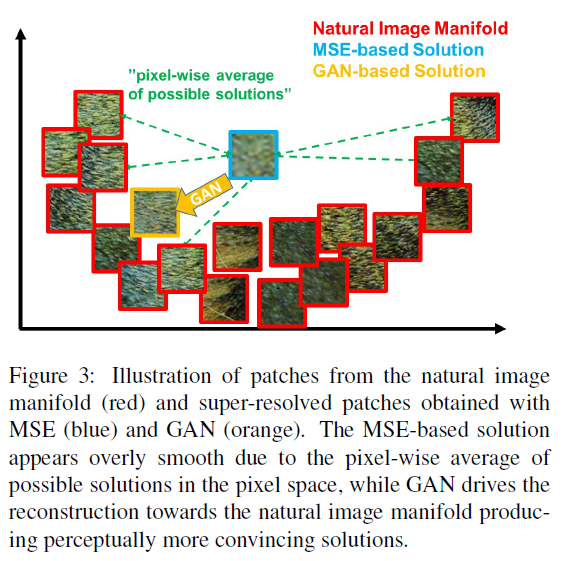
Pixel-wise loss function들, 그중 MSE는 texture와 같이 높은 주파수의 디테일들을 복원하기 위해서 노력한다. Pixel-wise 평균을 찾도록 MSE를 최소화 하는 것은 결국 과도하게 smooth되거나 굉장히 인지적으로 좋지 않은 결과를 만들어내고는 합니다. Figure 3은 MSE 최소화의 문제점을 보여주는데, 중간의 이미지는 MSE를 기반으로 하는 결과값이며 이는 주변에는 다양한 high texture detail들이 smooth reconstruct된 평균이라 할 수 있습니다. 그렇기 때문에 이 논문에서는 MSE 대신 perceptual similarity에 중점을 둔 loss function을 제시하였습니다. 이는 Johnson et al.과 Bruna et al.에서 제시된 pretrain된 VGG19 모델에서 추출된 feature map들 사이의 euclidean distance를 계산하는 방식이었습니다.
Contributions
저자는 이 논문이 기여한 바를 크게 3가지로 나누었습니다.
- 우리는 4배 upscaling SR에 있어서 PSNR 측정을 기준으로, MSE에 최적화된 16 블록 깊이의 SRResNet으로 SSIM을 기준으로 SOTA를 달성했다.
- 우리는 새로운 perceptual loss에 최적화 된 GAN을 기반으로 하는 SRGAN을 제시하였다. 우리는 MSE를 기반으로 하는 content loss를 VGG 네트워크의 feature map을 기반으로 계산된 loss로 대체하였고, 이는 픽셀 공간의 변화에 더욱 불변하다 할 수 있다.
- 우리는 MOS test에서도 좋은 성능을 보였다.
결론적으로는 SRResNet보다 성능이 좋고, GAN을 기반으로 하는 SRGAN이라는 모델을 제시했는데 이 성능이 MOS 테스트에서도 좋다라는것 입니다.
2. Method
- \(I^{HR}\): High resolution image, 오직 training 과정에서만 사용 가능
- \(I^{LR}\): Low resolution image, \(I^{HR}\)에 factor \(r\)의 값 만큼 가우시안 필터를 이용하여 다운 샘플링을 하면 \(I^{LR}\)
- \(I^{SR}\): Super resolved image, \(I^{LR}\)에 super resolution을 적용한 이미지
single image super resolution(SISR)은 \(I^{LR}\)로 부터 고화질의 super resolved된 이미지 \(I^{SR}\)을 추정하는 것이 목표입니다. \(C\)개의 채널이 있는 이미지라면, 실제 tensor의 사이즈가 \(W \times H \times C\)라면 \(I^{HR}\)과 \(I^{SR}\)은 \(rW \times rH \times C\)이 됩니다.
결국 이 논문의 궁극적인 목표는 주어진 LR 입력값을 상응하는 HR로 변환하기 위한 generating 함수 \(G\)를 학습시키는 것이며 아래의 수식을 해결하는 것 입니다. 그러한 과정에서 앞서 말한 perceptual loss \(l^{SR}\)을 디자인 하였고, 이에 대해 자세한 설명은 뒤쪽에서 설명하겠습니다.
- Generator network: \(G_{\theta_{G}}\)
- \(L\)개의 layer의 weight과 bias: \(\theta_{G} = \left\{ W_{1:L};b_{1:L} \right\}\)
- SR-specific loss function: \(l^{SR}\)
- Training image \(I_{n}^{HR}\), correspond to \(I_{n}^{LR}\), \(n=1, \ldots, N\)
Adversarial network architecture
\[\underset{\theta_{G}}{\min}\underset{\theta_{D}}{\max}\mathbb{E}_{I^{HR} \sim p_{train} \left(I^{HR}\right)}\left[\log D_{\theta_{D}} \left(I^{HR} \right) \right] + \\ \qquad\qquad\qquad\quad \mathbb{E}_{I^{LR} \sim p_{G} \left(I^{LR}\right)}\left[\log \left( 1 - D_{\theta_{D}} \left( G_{\theta_{G}} \left(I^{LR} \right) \right) \right) \right]\]이 식은 Goodfellow가 제안한 GAN loss를 구하기 위한 식입니다. 이 식의 목표는 super-resolved된 이미지를 실제 이미지와 구분하기 위해서 훈련된 미분 가능한 discriminator network \(D\)를 속이기 위한 generative model \(G\)를 학습하는 것을 가능하게 하는 것입니다. 이러한 접근을 통해서 이 논문의 generator는 \(D\)가 구분하기 매우 어려운 실제 이미지와 매우 유사한 solution을 생성하는 것을 학습할 수 있습니다. 이러한 부분이 super-resolution에서 MSE와 같은 pixel-wise error를 최소화 하는 것과 다른 점입니다.
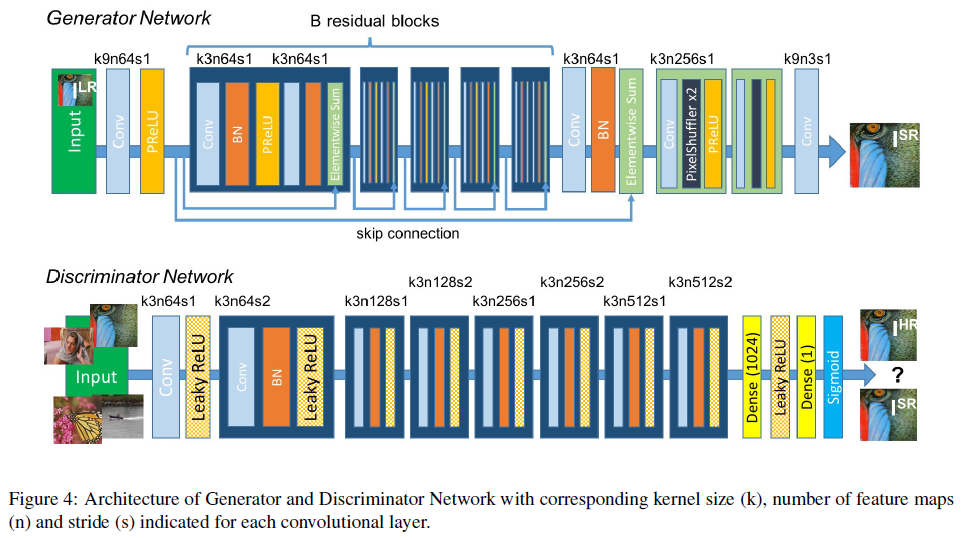
위의 이미지 figure 4는 generator와 discriminator network의 구조를 시각화 한 이미지입니다. 아주 깊은 generator network \(G\)는 이미지에 나와있는 것 처럼 똑같은 layout을 지닌 \(B\)개의 residual block이 존재합니다. 특히 이 모델은 \(3\times3\)의 작은 크기의 커널을 지닌 2개의 convolutional layer를 이용하며 batch normalization layer와 ParametricReLU가 따라오는 64개의 feature map을 activation function으로 이용하였습니다. 일반적으로 convolution layer를 이용하면 그 image의 차원은 작아지거나 동일하지만 super resolution은 image의 dimension을 증가시켜야 합니다. 여기서 pixel을 증가시키기 위해 이용된 방식이 sub-pixel convolution입니다. 이는 Shi et al.에서 소개된 방법으로 input image의 feature map을 논문에서 제시하는 방법으로 조합하여 pixel의 수를 증가시키는 방식입니다. 실제 HR 이미지와 SR에서 생성된 이미지를 구분하기 위해서 discriminator network를 학습시킵니다. 이 네트워크는 위의 수식의 maximazation 문제를 해결하기 위해서 학습된다. \(D\) network는 8개의 convolutional layer를 가지며 \(3 \times 3\)의 증가하는 filter kernel과 2의 인수로 VGG network처럼 64부터 512까지 증가하는 방식입니다.
Perceptual loss function
\[l^{SR} = l_{X}^{SR} + 10^{-3}l_{Gen}^{SR}\]이 논문에서 정의한 perceptual loss function \(l^{SR}\)은 generator network의 성능에 있어서 아주 중요한 역할을 합니다. 일반적으로 \(l^{SR}\)은 MSE에 기반하여 설계되지만, 이 논문에서는 실제로 인식하는 특징들과 관련이 있도록 loss function을 설계하였습니다. 이 논문에서는 perceptual loss를 content loss와 adversarial loss의 합이라 정의하였습니다. 아래에는 각각 content loss와 adversarial loss에 대한 설명입니다.
Content loss
일반적으로 사용되는 pixel-wise MSE loss는 아래의 식과 같습니다.
\[l_{MSE}^{SR} = \frac{1}{r^{2}WH}\sum_{x=1}^{rW}\sum_{y=1}^{rH}\left(I_{x,y}^{HR}-G_{\theta_{G}}\left(I^{LR}\right)_{x,y}\right)^{2}\]이 식은 PSNR을 향상 시키는데에는 좋은 효과를 보이지만, 사람이 보기에는 과하게 smooth하여 만족스럽지 못한 이미지들을 만들고는 합니다. 그래서 이런 pixel-wise loss에 의존하기 보단, pre-train된 19개의 layer를 같는 VGG network의 activation layer에 기반한 VGG loss를 새로 정의합니다. \(W_{i,j}\)와 \(H_{i,j}\)는 VGG network의 feature map에 관련된 dimension을 의미합니다.
\[l_{VGG/i.j}^{SR} = \frac{1}{W_{i,j}H_{i,j}}\sum_{x=1}^{W_{i,j}}\sum_{y=1}^{H_{i,j}}\left(\phi_{i,j} \left( \left(I^{HR}\right)_{x,y}\right) - \phi_{i,j}\left( G_{\theta_{G}}\left(I^{LR}\right)\right)_{x,y}\right)^{2}\]Adversarial loss
추가적으로 이 GAN모델의 generative한 부분도 perceptual loss에 추가되었습니다. 이것은 이 논문이 제시하는 network가 discriminator network를 속이기 위해서 자연 이미지의 다양성을 가질수 있도록 합니다. Generative loss인 \(l_{Gen}^{SR}\)는 discriminator \(D_{\theta_{D}} \left(G_{\theta_{G}}\left(I^{LR}\right)\right)\)의 확률을 기반으로 정의되었습니다.
\[l_{Gen}^{SR} = \sum_{n=1}^{N}-\log{D_{\theta_{D}} \left(G_{\theta_{G}}\left(I^{LR}\right)\right)}\]여기서 \(D_{\theta_{D}} \left(G_{\theta_{G}}\left(I^{LR}\right)\right)\)는 재구성된 이미지 \(G_{\theta_{G}}\left(I^{LR}\right)\)가 natural HR image일 확률이며, 더 나은 gradient를 위해서 \(-\log{D_{\theta_{D}} \left(G_{\theta_{G}}\left(I^{LR}\right)\right)}\)를 \(\left[\log{D_{\theta_{D}} \left(G_{\theta_{G}}\left(I^{LR}\right)\right)}\right]\) 대신 minimize하여 사용합니다.
3. Experiments
Mean opinion score (MOS) testing

실험의 데이터로는 super resolution에서 널리 이용되는 Set5, Set14, 그리고 BSD100이 이용되었습니다. 모든 실험은 LR과 HR 사이의 4배의 기준으로 수행되었으며 이는 pixel 사이즈가 16배 감소했다는 것을 의미합니다. 데이터는 ImageNet에서 \(350,000\)개의 랜덤한 이미지를 샘플링하여 학습시켰고 SRResNet의 경우에는 1,000,000번의 epoch을, SRGAN의 경우에는 100,00번의 epoch을 train하였다. 또한 convincing image들을 재구성하는 다양한 접근의 ability를 정량화하기 위해서 MOS test를 실행하였습니다. 이는 26명의 사람에게 이미지를 1(나쁨) 부터 5(좋음)로 이미지를 평가하도록 하였고, 각 이미지의 12개의 버전을 평가하였습니다. 이 test 결과는 좋은 신뢰도를 보였으며, figure 5의 표에서 사람들의 SRGAN의 결과를 다른 모델에 비해 좋게 평가했음을 확인할 수 있습니다.
Investigation of content loss
이 논문에서는 GAN-based netwrok의 perceptual loss에 대해서 여러 다른 content loss의 효과에 대해서 조사하였습니다. Table 1은 SRResNet과 SRGAN에 대해 \(l^{SR} = l_{X}^{SR} + 10^{-3}l_{Gen}^{SR}\)에서 어떤 \(l_{X}^{SR}\)을 선택하느냐에 따라서 바뀌는 결과값들에 대한 표입니다.
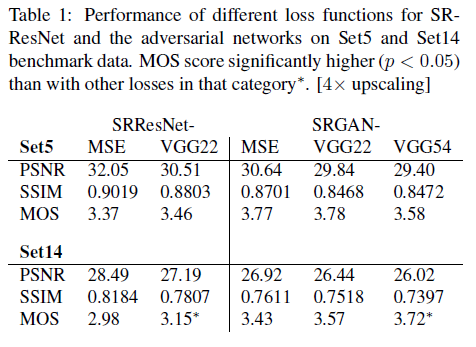
- SRGAN-MSE: \(l_{MSE}^{SR}\), 표준 MSE와 함께 있는 adversarial loss를 분석하기 위함
- SRGAN-VGG22: \(l_{VGG/2.2}^{SR}\) with \(\phi_{2,2}\), lower-level feature를 대표하는 feature map에 define된 loss
- SRGAN-VGG54: \(l_{VGG/5.4}^{SR}\) with \(\phi_{5,4}\), higher-level feature를 대표하는 feature map에 define된 loss이며 뒤따라 설명되는 SRGAN입니다
위의 표를 보면, MSE를 이용한 모델들이 대체적으로 더 좋은 PSNR 값을 얻었다고 할 수 있습니다. 이는 앞서 말했듯이 서로 역관계이기 때문에 나타나는 경향입니다. 이 표에서는 Set5에 대해서는 어떤 방식이 더 좋다 라고 결정 지을 수는 없지만, Set14에서는 SRGAN-VGG54가 다른 모델들을 MOS를 기준으로 압도했다고 할 수 있습니다. 이는 이 모델이 질감이나 디테일한 부분에 있어서 더 잘 표현되었기 때문에 그럴것이라 추측할 수 있습니다.

Figure 6에서 각 모델의 결과값들을 확인해 볼 수 있습니다. 실제로 SRResNet이나 다른 SRGAN 모델들과 비교해 보았을 때, SRGAN-VGG54가 사람이 보기에 좀 더 디테일한 부분들과 이미지의 질감을 잘 살렸다고 볼 수 있음을 확인할 수 있었습니다.
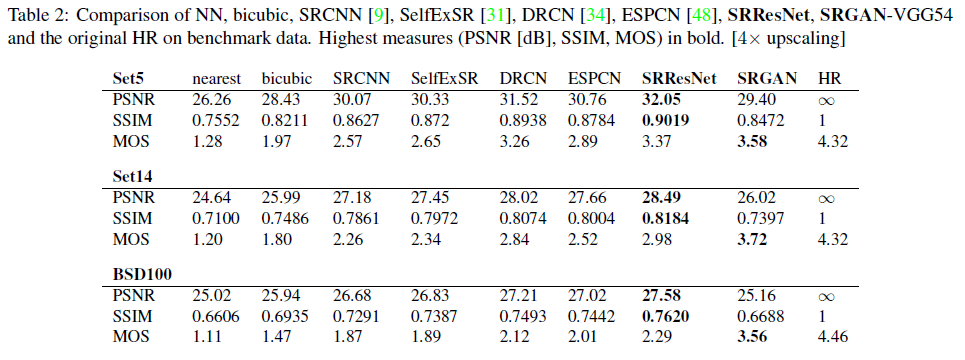
Table 2는 벤치마크 데이터에 대해서 여러 방법들을 비교한 표입니다. PSNR과 SSIM 값의 경우에는 SRResNet이 두드러지게 높은 값을 보였으며, MOS값은 SRGAN이 높은 값을 지니는 것을 확인할 수 있었습니다. 이를 통해 사람들이 이미지를 인식할때 PSNR이나 SSIM 값이 매우 높지 않아도 좋은 이미지라 인식할 수 있으며, 사람 기준의 high resolution이 다를 수 있다라는 것을 보여주었습니다.
4. Discussion and future work
- SRGAN이 MOS testing에서 상당한 성능을 보임을 확인할 수 있었습니다.
- 이전의 연구, Dong et al.와는 반대로, 더 깊은 network 구조가 더 좋은 성능을 보임을 확인할 수 있었습니다.
- Network가 깊은 경우에는 high-frequency artifact의 출현으로 상당히 train하기가 힘듬을 발견하였습니다.
- Loss function은 어떻게 사용하느냐에 달려 있습니다.
댓글남기기