
EDSR baseline에 cutblur가 미치는 영향
업데이트:
이 논문에 대한 실험을 재현해보았습니다. 코드는 github에서 제공된 코드를 이용하였습니다.
Environment
- GPU: GeForce RTX 2080Ti, CUDA 10.2
- OS: Ubuntu 18.04.4 LTS
- PyTorch: 1.4.0, torchvision: 0.4.0
Cutblur

Cutblur는 mixup, cut-out, cutmix와 같은 data augmentation이 backbone model의 일반화 성능을 올리는데에 기여한 것 처럼, low-level vision task인 super resolution에 적용 가능한 augmentation 기법입니다. Clova AI Research에서 개발한 기법으로 CVPR2020에서 발표되었으며 x4 scale의 이미지들에서 상당히 개선된 성능을 확인할 수 있습니다. 이 방식은 위의 이미지 처럼 HR 이미지의 부분을 잘라서, 잘린 부분을 LR 이미지로 대체하여 학습 데이터로서 이용하는 방식입니다.
Experiment
EDSR baseline 모델은 16개의 Residual block, 64개의 filter로 이루어져 있는 모델입니다. 학습을 위해서는 DIV2K 데이터 셋을 이용하였고, 이중 800개는 training image, 100개는 validation, 그리고 나머지 100개는 test를 위한 이미지 입니다. 이 실험은 데이터 변형 없이, cutblur만, 그리고 다른 augmentation도 모두 적용된 3개의 모델에 대해서 학습을 시켰습니다. 모델은 x2 scale에 대해서 학습되었으며, 총 3개의 데이터셋에 대해서 evaluate 되었습니다.
PSNR of training
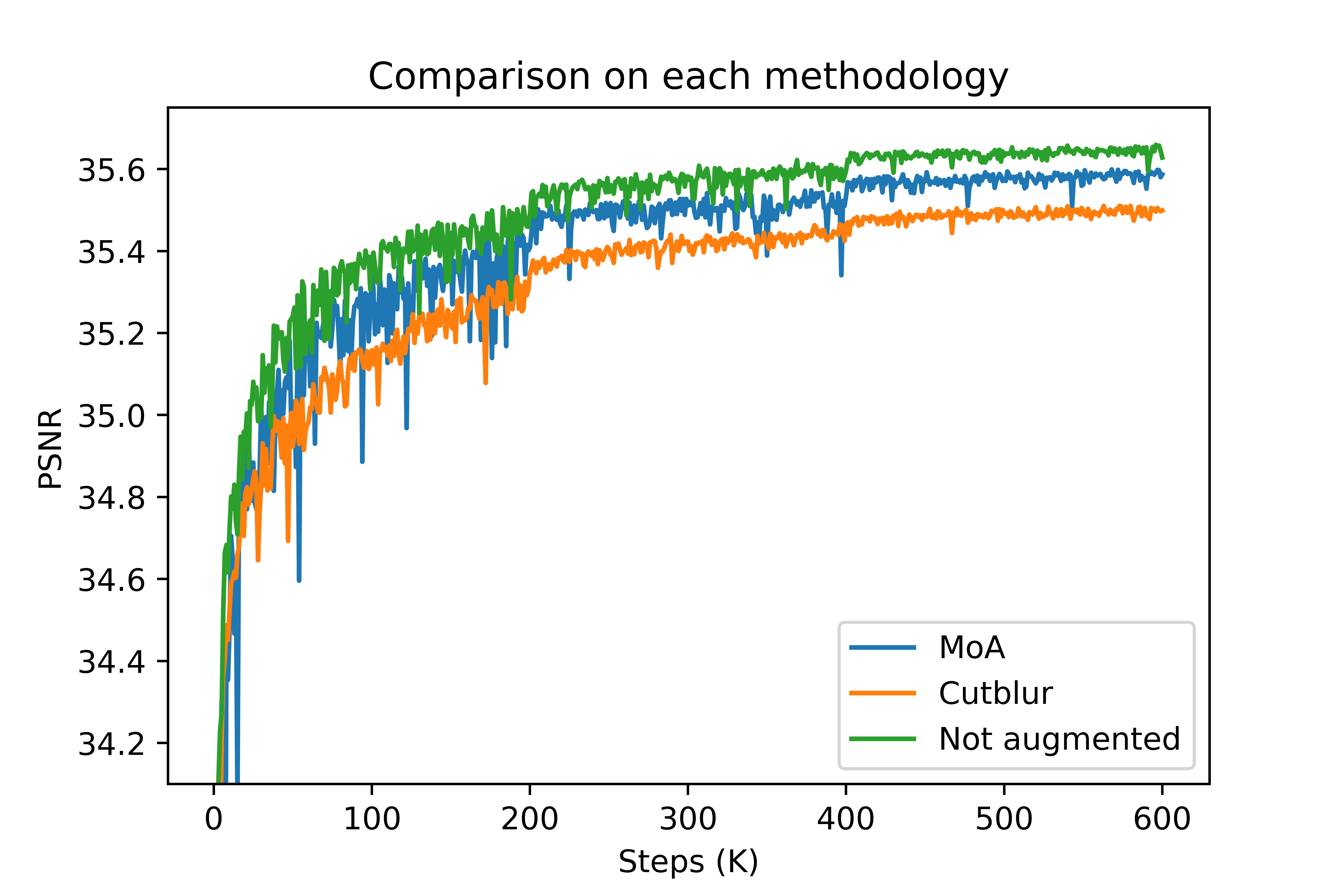
그래프를 보면 오히려 변형이 가해지지 않은 데이터로 학습된 모델이 더 좋은 PSNR 값을 보이고 있음을 확인할 수 있었습니다. 실제 논문에서는 x4 scale에 모델에 대해서 test된 결과값을 소개하고 있어서, 이후에 다시 x4 scale에 대해서도 모델을 학습시키고자 합니다.
PSNR of each model
| Model | Set14 | Urban100 | DIV2K |
|---|---|---|---|
| Cutblur | 33.39 | 31.71 | 34.47 |
| MoA | 33.47 | 31.89 | 34.55 |
| Aug X | 33.56 | 32.04 | 34.62 |
위의 학습중의 validation 값처럼 각 test dataset에 대해서도 데이터 변형이 되지 않은 모델이 가장 좋은 성능을 보이고 있음을 확인할 수 있었습니다. 실험의 결과가 실험상에서의 오류로 발생된 문제인지, 아니면 실제로 이런 결과를 보이고 있는 것인지 확인이 필요합니다.
Result of super resolution
Urban100
| HR | MoA | Cutblur | AugX |
|---|---|---|---|
 |
 |
 |
 |
댓글남기기