
[논문] Enhanced Deep Residual Networks for Single Image Super-Resolution
업데이트:
Super resolution과 관련된 연구들은 CNN(Convolutional neural network)의 깊이가 깊어짐에 따라 점점 발전되었습니다. 이 논문에서 제시하는 모델은 더 향상된 Deep super-resolution network로 당시의 SOTA 성능을 넘는 네트워크를 제시하였습니다. 또한 단일 모델에서 여러 배율의 upscaling이 적용 가능한 모델인 MDSR(multi-scale deep super-resolution system)을 제시하였습니다.
1. Introduction

일반적으로 초해상화 기법에 대한 연구를 진행할때는 bicubic으로 downsample된 이미지를 이용하여 모델을 학습시킵니다. 하지만, 실제로는 bicubic이 아닌 noise와 같은 다양한 방식으로도 이미지의 화질이 저하 될 수 있습니다. 최근의 DNN들은 super-resolution에서 향상된 PSNR(peak signal to noise ratio)를 보이지만, 실제 네트워크들은 구조의 최적화적인 면에서 그 한계를 보이고 있습니다. 첫째로, 신경망 모델을 재구성 하는 경우에 상당히 민감함을 보였습니다. 둘째로, 대부분의 존재하는 SR 알고리즘은 모델에 한번에 한가지의 배율에만 적용될 수 있다는 점 이었습니다. 예외적으로 VDSR이라는 모델이 존재하지만, 이 논문에서 제시한 MDSR과 비교해서 더 많은 연산과 메모리를 요구합니다. 원래의 ResNet은 image classification과 같은 분야에 적용되도록 만들어졌으므로, SR과 같은 분야에 이용되는 것은 최적이 아닐 수도 있습니다.
이러한 문제들을 해결하기 위헤서 이 논문에서는 SRResNet을 기반으로 하여 모델에서 필요없는 부분을 제거하고, 3, 4 배율을 학습하는데에 pre-train된 2배율 학습 모델을 사용하여 한번에 여러 배율이 확대 가능한 모델을 생성했습니다. 모델이 복잡할수록 학습이 어렵기 때문에 적절한 loss function과 신중한 모델 구조 수정을 통해서 네트워크를 설계했습니다. 이 논문은 DIV2K 데이터 셋을 이용하여 평가되었으며 PSNR, SSIM에서 SOTA를 달성, NTIRE 2017 super-resolution challenge에서는 1위를 차지 하였습니다.
2. Related Works
최초의 super-resolution problem에 대한 접근은 sampling theory를 기반으로 하는 interpolation technique을 기반으로 하였습니다. 하지만 이런 방법들은 디테일한 부분들을 예측하는데에 한계를 보였고, 이전의 연구들은 더 나은 고화질의 이미지를 만들기 위해서 자연 이미지의 통계를 문제에 적용하였습니다. 그리고 최근에는 DNN을 SR에 적용하여 SR의 성능이 크게 향상되었습니다. 또한 더 깊은 네트워크를 학습시키기 위해서 residual 구조를 적용하였고 skip-connection과 recursive convolution network가 빠르고 향상된 수렴을 보였습니다.
많은 딥러닝 기반의 super-resolution에서 입력 이미지는 bicubic interpolation을 이용하여 이미지를 upsample합니다. 그 외에는 SRGAN처럼 모델의 끝에서 upsampling을 학습할 수도 있습니다. 하지만 이런 방식은 VDSR과 같이 하나의 모델에서 여러가지 scale을 다루는 것을 어렵게 만듭니다. 그래서 이 논문에서는 각 스케일에 대해서 학습된 모델을 잘 활용하고, 여러 스케일에 대한 HR 이미지를 효율적으로 만드는 MDSR을 제안합니다. 또 다른 연구들은 모델을 더 잘 학습시키기 위해서 loss function에 집중하기도 합니다. MSE 또는 L2 loss function이 가장 흔히 이용되는 함수인데, Zhao et al.에 의하면 L1 loss function의 성능이 더 좋다라고 제시합니다.
3. Proposed Methods
이 논문에서는 특정 SR을 처리하는 EDSR과 다양한 스케일의 SR을 만드는 MDSR을 제시합니다.
3.1. Residual blocks
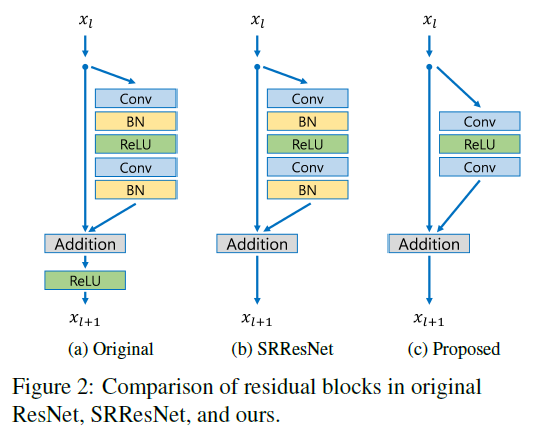
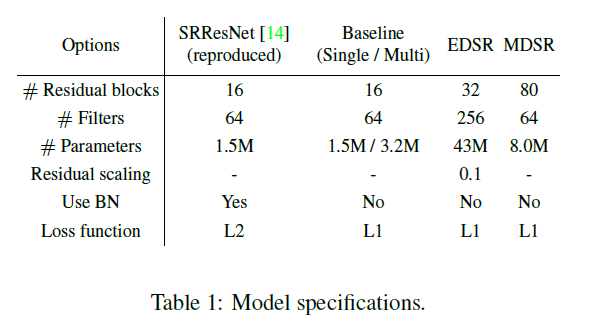
Figure 2에서는 원래의 ResNet, SRResNet, 그리고 논문에서 제시한 모델의 구조를 비교하고 있습니다. 이 그림에서 간단하게 구조에서 batch normalizaion과 ReLU가 빠졌음을 확인할 수 있었습니다. Batch normalization이 feature를 normalize해버리기 때문에 오히려 모델의 유연성이 제거되므로, BN 레이어는 제거되는것이 좋습니다. 또한, 이를 제거함을 통해서 GPU 메모리의 사용량도 줄일 수 있습니다.
3.2. Single-scale model
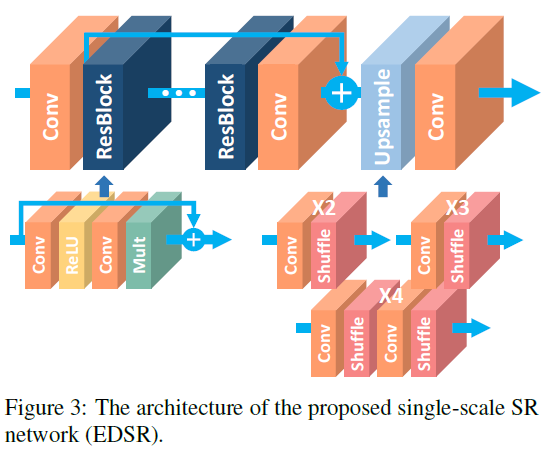
네트워크 모델의 성능을 향상시키는 가장 간단한 방법은 파라미터의 수를 증가시키는 것 입니다. CNN에서는 모델의 성능을 필터의 수를 증가시키고 여러 레이어를 쌓음을 통해서 향상시킬 수 있습니다. $B$를 레이어의 수, $F$를 feature 채널의 수라고 할 때, 일반적은 CNN 구조의 네트워크는 $O\left(BF\right)$의 메모리 공간을 $O\left(BF^{2}\right)$개의 파라미터로 채웁니다. 하지만, 이렇게 feature의 수가 증가할 지라도, 일정 수준 이상으로 feature를 증가시키는 것은 학습 과정을 더 불안정하게 만들 수 있습니다. 이를 해결하기 위해서 residual scaling의 값을 0.1로 설정하고 각각의 residual block의 마지막 convolution layer 뒤에서는 constant scaling layer를 추가합니다. 이러한 모듈은 아주 많은 필터를 지닌 모듈을 학습과정에서 안정화 시킵니다. 이 논문에서는 baseline(single-scale) 모델을 figure2에서 제시된 구조를 이용하였으며, 앞서 말한 scaling layer를 넣지 않았습니다. 왜냐하면 이 논문은 각각의 convolution layer에 대해서 64개의 많지 않은 feature map을 이용했기 때문입니다. 이 논문의 최종 EDSR에서는 $B=32$, $F=256$으로 scaling factor 0.1을 사용하였습니다. x3, x4 scale의 모델을 학습할 경우에는 x2로 사전 학습된 모델의 파라미터로 초기화 시켜서 학습을 했습니다. 이에 대한 결과는 위의 표에서도 보여지듯, 좋은 결과를 냈음을 확인할 수 있었습니다.
3.3. Multi-scale model
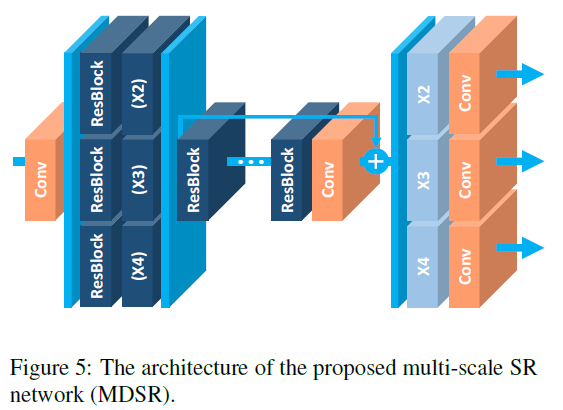
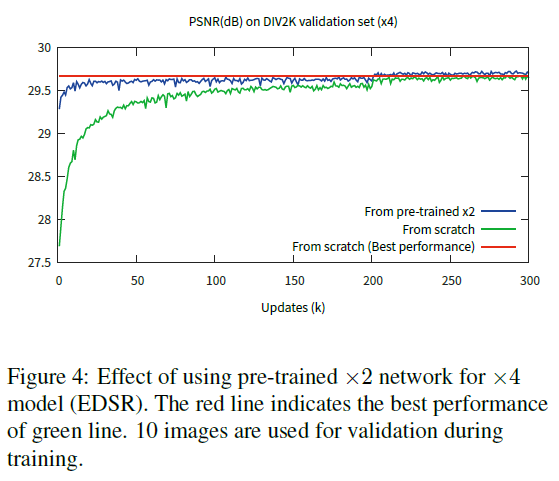
위의 figure 4를 통해서 각각의 스케일에 상관 없는 유사성이 있다 생각해 볼 수 있습니다. VDSR과 같은 multi-scale 네트워크를 만들기 위해서 다른 스케일의 파라미터들을 공유하는 구조를 본 논문에서는 소개합니다. 전처리 모듈은 네트워크의 앞쪽에서 여러 스케일의 이미지들 간의 편차를 줄입니다. 이때, 전처리 모듈은 $5\times5$의 커널을 지난 두개의 residual block으로 구성됩니다. 모델의 끝에는 특정 upsampling 모듈을 멀티 스케일 재구성을 위해서 전처리 모듈과 마찬가지로 병렬적으로 배치합니다. 결과적으로 $B=80$, $F=64$의 MDSR 모델을 구성합니다. 단일 스케일만 변환이 가능한 경우에는 한 모델당 약 1.5M의 매개변수가 필요하므로 총 4.5M개의 변수를 지닌 반면, baseline 다중 스케일 모델의 경우에는 3.2M개의 매개 변수만을 필요로 합니다. 그럼에도 불구하고 모델의 성능은 단일 스케일 모델과의 성능이 유사함을 확인할 수 있습니다.
4. Experiments
4.1. Dataset

- DIV2K
- 이 논문에서는 학습을 위해 DIV2K를 이용하였으며, 이 데이터 셋은 800장의 training 이미지, 100장의 검증 이미지, 그리고 100장의 test 이미지로 이루어져 있습니다.
- Train/Test
- Matlab bicubic으로 2, 3, 4배 축소되어 만들어진 low resolution(LR) 이미지
- 어떻게 LR이 되었는지 알 수 없는 2, 3, 4배 축소된 이미지
- Benchmark Dataset
- Set5, Set14, BSD100, Urban100
- 학습을 위해 LR 이미지에서 $48 \times 48$ 크기의 RGB 입력 패치를 대응되는 HR 패치와 함께 사용합니다. (2K 이미지를 한번에 넣기에는 모델의 크기가 감당할 수 없음)
4.2. Training Details
- Data augmentation
- 90도 회전, 수평 뒤집기
- Optimization
- ADAM
- 먼저 2배 스케일에 해당하는 모델을 학습하고, 이후 다른 모델의 파라미터로 활용합니다.
- MDSR은 미니 배치를 하는 경우에 임의의 스케일을 선택합니다.
- 해당하는 스케일에 대해서만 업데이트를 하며, 다른 스케일에 대해서는 residual block이나 upsampling을 활성화하지 않습니다.
- Loss function으로는 L1 loss를 이용합니다.
- EDSR과 MDSR은 NVIDIA Titan X GPU에서 각각 4일, 8일 소요되었습니다.
4.3. Geometric Self-ensemble
모델의 잠재적인 성능을 더욱 최대화 하기 위해서, 이 논문에서는 self-ensemble 전략을 적용하였습니다. 이 방식은 테스트 하는 동한 input 이미지를 데이터 변형을 통해 7개를 만들어 총 8개의 이미지를 생성하는 방식으로, 생성한 이미지들을 이용하여 8개의 SR 이미지를 생성합니다. 그리고 생성된 8개의 이미지를 이용하여 최종 SR 이미지를 생성합니다. 이는 추가적인 모델 학습이 요구되지 않으며, 이 방법이 적용된 모델은 모델 이름 뒤에 EDSR+/MDSR+ 처럼 ‘+’가 추가 됩니다. 이 방식은 bicubic down sampling과 같은 방식으로 down sample된 이미지에만 유효한 방식입니다.
4.4. Evaluation on DIV2K dataset
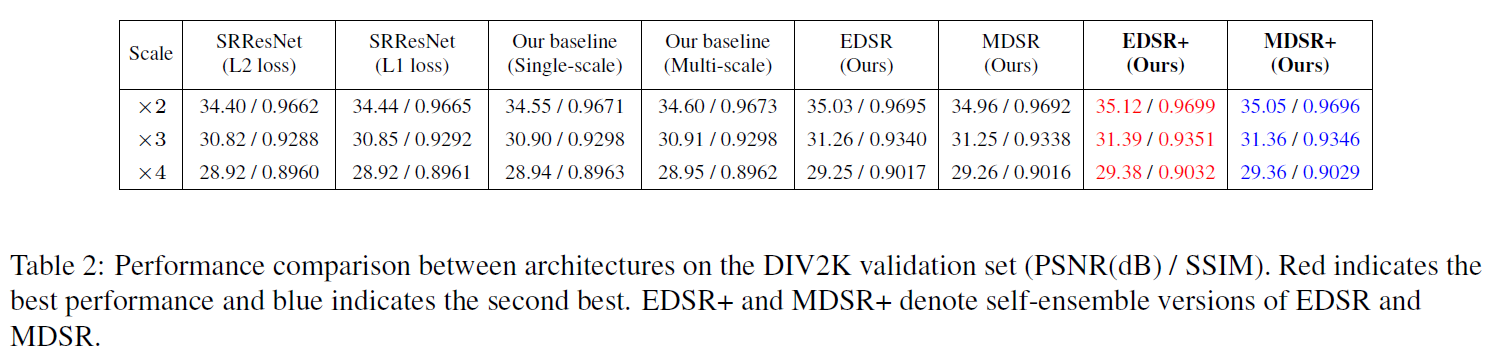
이 논문에서는 SRResNet부터 제시된 모델들에 대한 DIV2K 데이터 셋에 대해서 실험을 진행하였습니다. SRResNet의 경우에는 L1 loss function을 이용하여 학습시킨 모델이 더 좋은 성능을 보였고, EDSR+와 MDSR+에서는 상당한 성능의 향상을 볼 수 있었습니다.
4.4. Benchmark Results
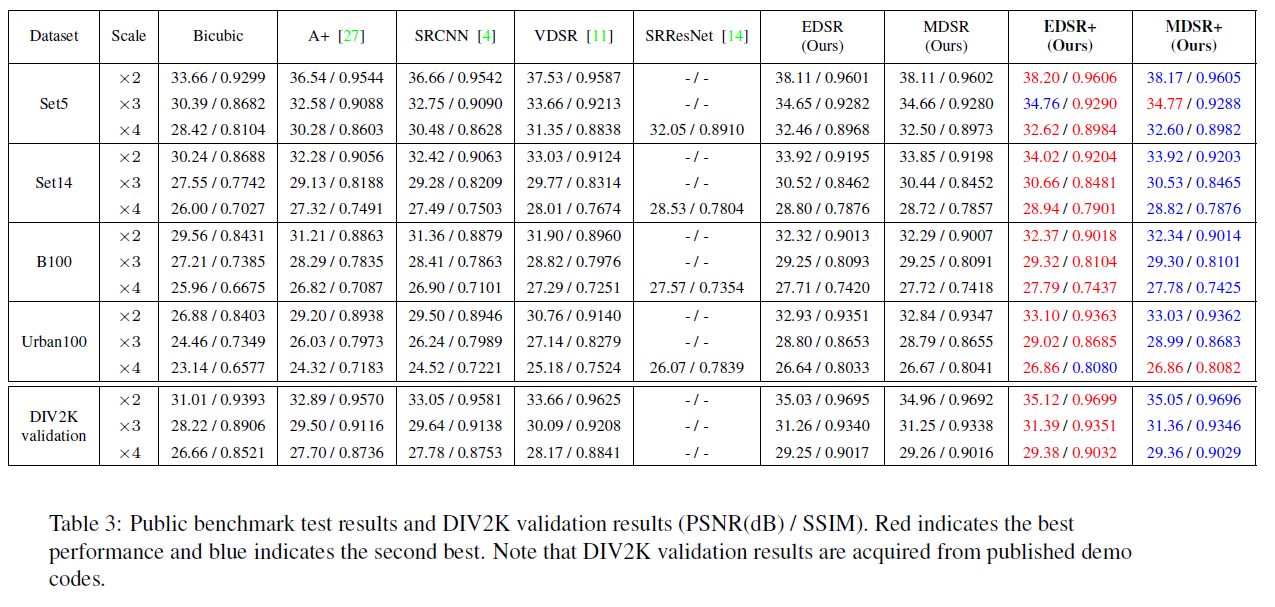
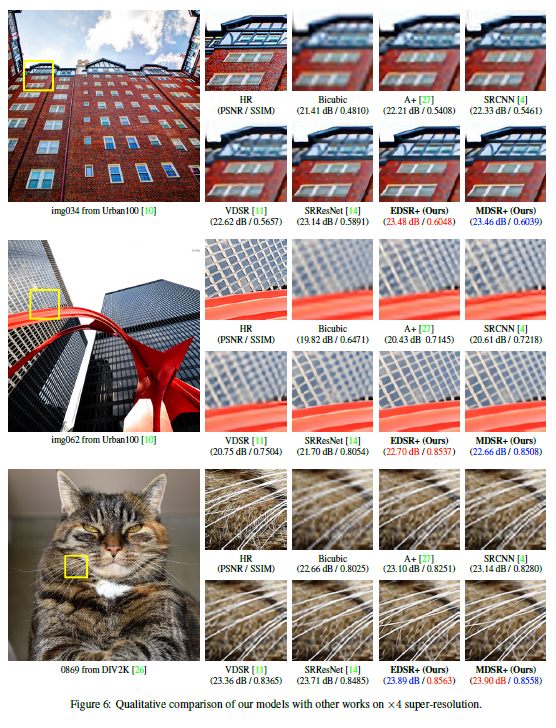
EDSR+와 MDSR+ 모델에 대해서 benchmark dataset에 대한 성능도 측정했습니다. 이에 대한 결과 이미지는 figure 6에서 확인할 수 있으며, 이 논문에서 제시한 모델들이 성공적으로 detail에 대한 부분과 edge를 다른 모델의 SR 이미지들과 비교하였을 때, 더 잘 살린 것을 확인할 수 있습니다.
5. NTIRE2017 SR Challenge
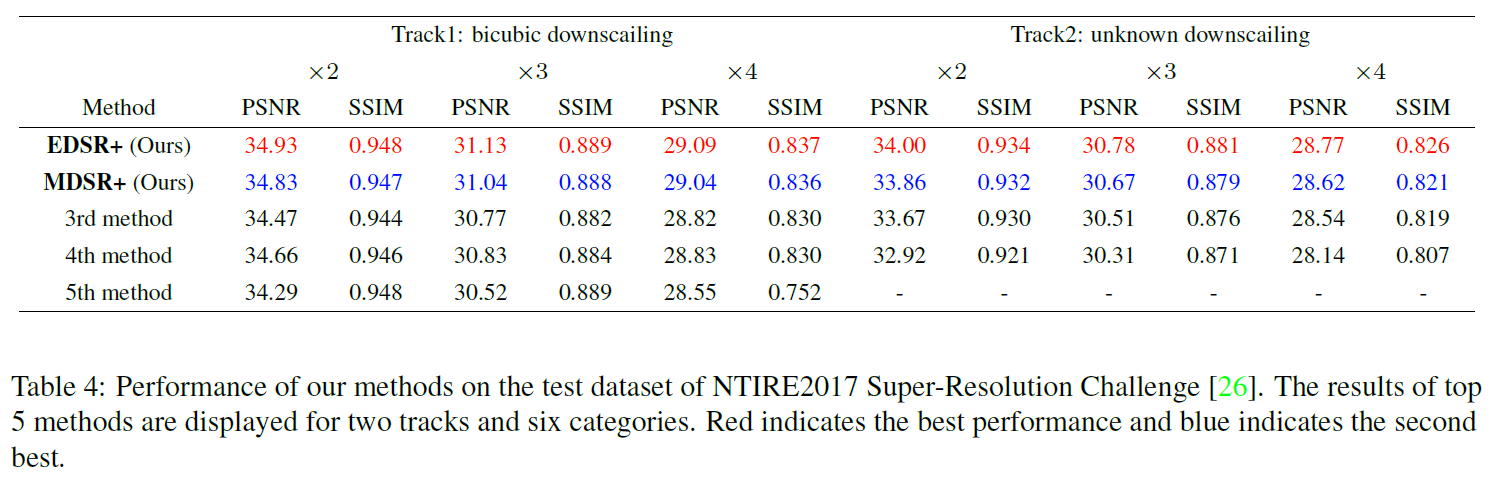
이 모델은 2017년도의 초해상도 복원 경진대회(NTIRE challenge on example-based single image super-resolution)에서 1등을 한 모델입니다. 위의 테이블에서는 이 대회에서 1, 2등을 차지한 논문에서 소개한 모델의 성능과, 3, 4, 5위의 모델의 성능을 보여주고 있습니다. Figure 7에서는 매우 degrade된 저화질 이미지에서 성공적으로 재구성한 이미지들을 보여주고 있습니다. Figure 7에 이용된 이미지들은 bicubic을 거친 이미지가 아니기 때문에, ‘+’ geometric self-ensemble을 사용하지 않았습니다.

댓글남기기