
MFCC (Mel-Frequency Cepstral Coefficients)
업데이트:
MFCCs (Mel-Frequency Cepstral Coefficients)
MFCC는 음성 인식을 위해 음성 데이터에서 가공된 feature입니다. 음성 도메인에 있어서 널리 사용되는 방식이며 가장 기본적인 음성 신호 전처리 방법이라 할 수 있습니다.
MFCC 추출 과정
음성 파일은 일정한 시간 간격을 갖고 특정 지점의 음압을 측정한 것입니다. Sampling rate는 이런 음성 파일이 초당 몇회 sampling 되었는지를 정의합니다 (Sampling rate의 단위는 Hz). Sampling rate와 관련한 더 자세한 내용은 여기에 설명되어있으며, 아래의 예제에서 사용된 파일은 .wav 파일로 sampling rate의 값은 16,000 Hz입니다.
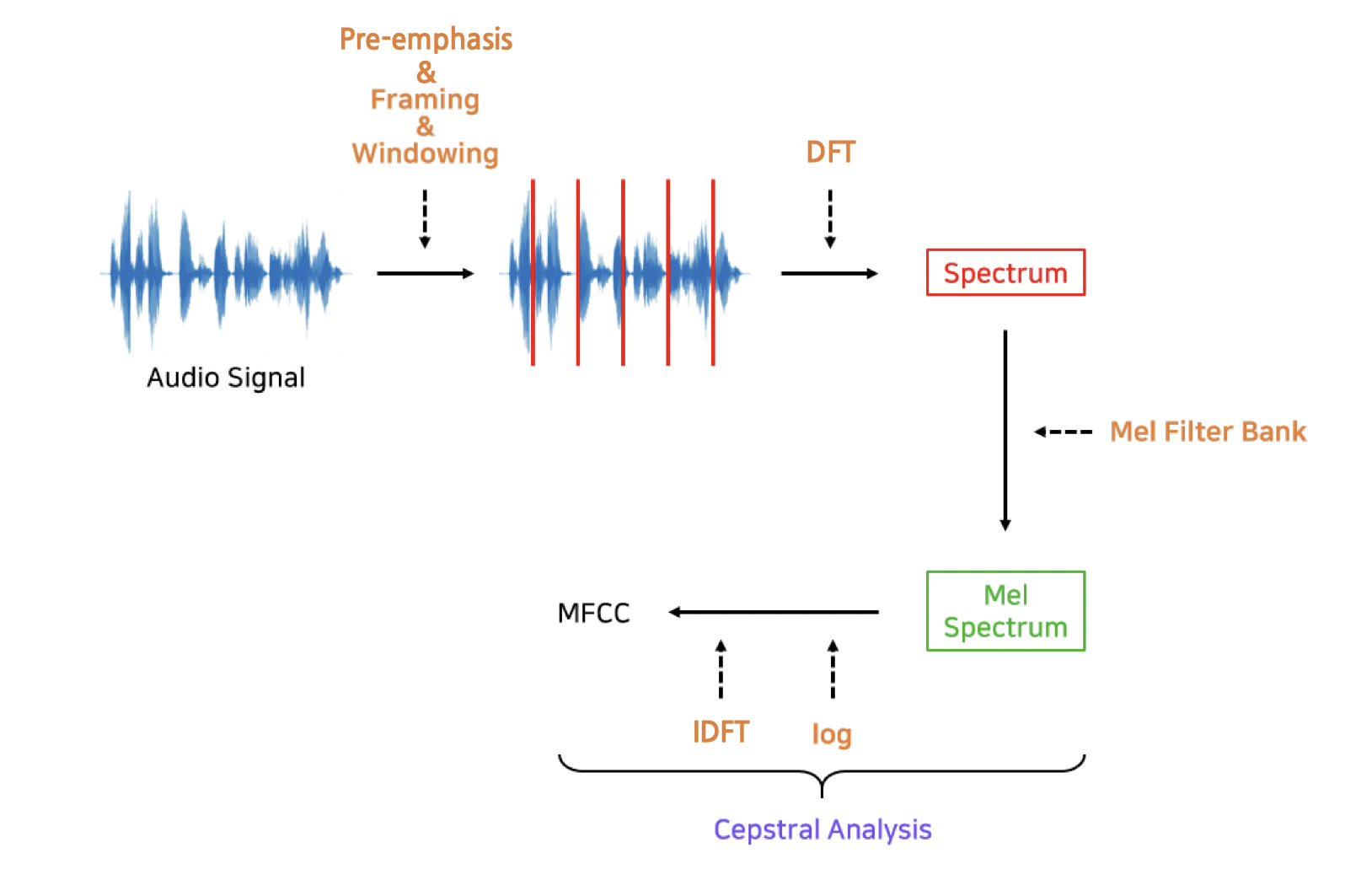
위의 그림은 음성 파일로 부터 mfcc가 추출되는 과정을 나타낸 그림입니다.
How to extract MFCCs from video?
Environment setup
-
Install FFMPEG.
sudo apt install ffmpeg -
Install librosa.
pip install librosa
.wav extraction from .mp4
-
Extract audio from videos.
for file in <input_dir>/*; do filename=$(basename $file .mp4); ffmpeg -y -i $file -ac 1 -f wav <output_dir>/${filename}.wav; done
Convert .wav to mfcc
-
librosa를 이용해서 MFCC를 추출한다.
import librosa filepath = 'filepath' signal, sr = librosa.load(filepath, sr=16000) MFCCs = librosa.feature.mfcc(signal, sr)
댓글남기기