
NeurIPS 2020: Review
업데이트:
2020년도 NeurIPS에 accept된 논문들 중 몇가지 간단하게 정리한 글입니다.
Rethinking the Value of Labels for Improving Class-Imbalanced Learning
- class-imbalanced learning
- unlabeled data
- semi-supervised, self-supervised learning
이 논문은 imbalanced learning에서 label의 가치가 어떤지에 대해서 다시 재고하는 논문입니다. 이 논문에서는 imbalanced label의 긍정/부정 두가지 가치에 대해서 다루었습니다. 긍정적인면으로는 unlabeled 데이터를 활용한 semi-supervised 학습을 통해 label bias를 해소할 수 있다라는 것입니다. semi-supervised 학습으로는 간단한 pseudo-label 방식을 활용하여 classifier의 성능을 개선하였습니다. 반면에 부정적인 면으로는 imbalanced label이 항상 유용한 것은 아니며, 오히려 unlabeled 데이터를 활용한 self-supervised 학습된 모델보다 그 성능이 더 좋지 않은 경우가 있다라고 말하고 있습니다. 이는 불균형의 정도에 따라서 label을 사용하지 않고 학습하는 경우의 오차가 그렇지 않은 경우보다 더 적게 나온 사실에 기반하여서 진행되었습니다. 초반에 모델을 학습시킬 때 label을 배제하고 학습시키며, 이렇게 pre-train된 모델의 성능이 이후에 어떤 technique이 적용된 모델이더라도 그 성능을 넘지 못함을 보였습니다.
여기서 이야기하는 주요 기여는 imbalacned label의 두가지 면에 대해서 분석했으며, unlabeled data를 활용하는 것이 imbalanced learning의 성능을 증폭시킬 수 있고, 마지막으로 추가 데이터의 사용 없이 class-imbalanced learning의 self-supervised pre-train 방식을 소개했다는 점입니다.
Not All Unlabeled Data are Equal: Learning to Weight Data in Semi-supervised Learning
- unlabeled data
- semi-supervised learning
- influence function
- optimization
현존하는 semi-supevised algorithm은 label 데이터와 unlabel 데이터의 규형을 맞추는데에 하나의 weight만을 이용합니다. 이 논문에서는 모든 unlabeled example에 대해서 어떻게 다른 weight를 이용할지에 대해서 연구했습니다. 수동으로 사람이 직접 모든 가중치를 조정하는 것은 불가능한 일이기 때문에 여기서는 influence function을 통해서 한 학습 예제에 모델이 얼마나 의존적인지를 측정합니다. 이 논문에서는 빠르고 효과적인 influence function을 제시하며, 이 기술이 semi-supervised image, language classification에서 좋은 성눙을 거두었다 합니다.
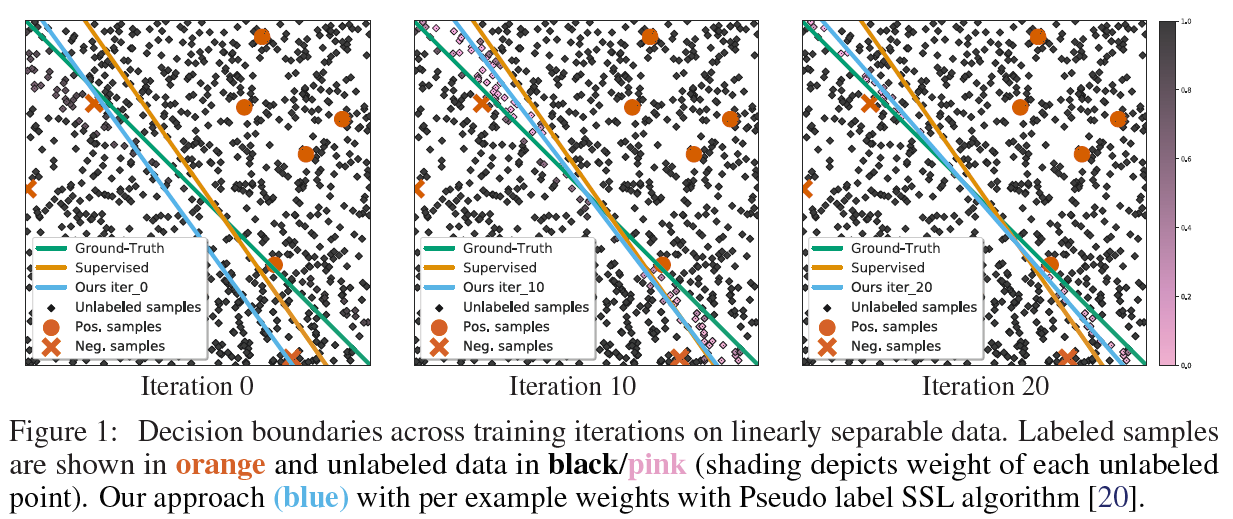
위의 그림은 검은색은 unlabeled 데이터이며, iteration에 따라서 점점 decision boundary와 데이터의 weight가 바뀌는 것을 보여준다. Decision boundary는 ground truth 그리고 supervised 모델과 비교되며, 본 논문에서 제시된 방식의 decision boundary가 ground truth과 조금 더 유사하다는 것을 볼 수 있습니다. 또한, ground truth와 proposed method 사이의 unlabeled data는 그 weight가 감소해있는 것을 볼 수 있습니다.

이 알고리즘은 논문에서 소개한 influence function을 통해서 weight를 최적화 시키는 방법인데, 이 알고리즘은 예제마다 gradient 계산을 필요로 하며 모델 파라미터의 inverse Hessian vector product의 계산이 필요합니다. 이러한 점을 해결하기 위해서 backpropagation의 확장을 통해 예제마다의 gradient 계산을 좀 더 효율적으로 만들고, 효과적인 최적화된 계산을 만들었다 합니다. 자세한 내용은 논문에서 확인할 수 있습니다.
Unsupervised Data Augmentation for Consistency Training
- data augmentation
- semi-supervised learning
이 논문은 supervised learning에서 성능 향상에 도움이 되는 advanced data augmentation이 semi-supervised에서도 적용이 가능한지에 대해서 연구한 논문입니다. Semi-supervised learning에 적용되는 data augmentation은 모델이 입력값의 작은 변화에도 consistency를 유지하도록 이미지에 노이즈를 입히는 방식이 입니다. Supervised learning에 적용되는 일반적인 data augmentation으로는 회전, 잘라내기, 확대와 같은 방법들이 존재합니다. 이 논문에서는 그러한 두 방식의 data augmentation의 장점을 이용하여 semi-supervised learning에서 좋은 성과를 이루었습니다.
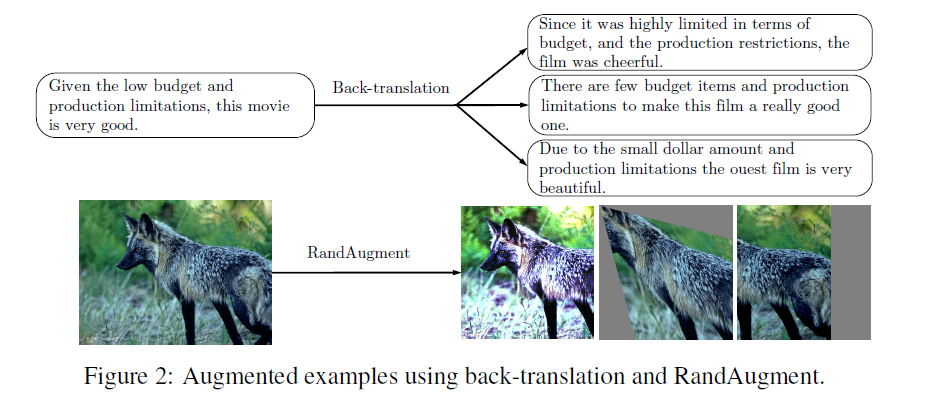
먼저 각 다른 task에 사용되는 다른 data augmentation들을 소개합니다. RandAugment는 이미지 분류에, Back-translation과 TF-IDF는 텍스트 분류에 이용됩니다. RandAugment는 AutoAugment에서 기인한 방식으로 AutoAugment는 모든 이미지 변형을 고려하여 가장 좋은 data augmentation을 찾는 방식이지만, RandAugment는 탐색 없이 동일하게 transformation을 적용합니다. Data augmentation외에도 confidence based masking, sharpening predictions, domain-relevance data filtering과 같은 방식을 이용하였습니다.
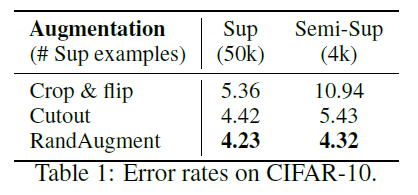
Vision task인 CIFAR-10 데이터에 대한 결과 값을 간단하게 본다면, supervised와 semi-supervised의 경우 crop&flip의 성능은 상당한 차이가 났지만 cutout에서는 그 차이가 매우 줄었고 RandAugment의 경우에는 두 방식 모두 큰 성능의 차이가 없음을 확인할 수 있었습니다. 뿐만 아니라 semi-supervised의 성능이 오히려 supervised의 cutout과 crop&flip보다 뛰어남을 확인할 수 있었습니다. 이러한 결과를 통해서 supervised learning에서 성능을 향상시키는 data augmentation은 semi-supervised에서도 적용이 가능함을 확인할 수 있었습니다.
Posterior Re-calibration for Imbalanced Datasets
- class-imbalanced learning
- optimization
이 논문에서 제시하는 문제 상황은 두가지입니다. 이는 학습 데이터가 심히 imbalanced하여 학습 데이터의 분포와 검증 데이터의 분포가 다른 경우와 class의 분포들이 중요한 관계성을 반영하지 않는 경우입니다. 이런 경우에는 testing label의 분포를 target으로 모델을 re-train해야하지만, 여기서는 그렇지 않고 최적화된 Bayes classifier를 이용하여 rebalanced posterior를 고안해냈습니다. 논문에서는 6개의 데이터셋과 5개의 신경망 모델을 통해서 해당 방법의 유효함을 검증하였습니다.
Distribution Aligning Refinery of Pseudo-label for Imbalanced Semi-supervised Learning
- unlabeled data
- semi-supervised learning
- imbalanced data
이전의 연구들은 대부분 labeled data와 unlabeled data들의 분포가 balanced 되어있다고 가정합니다. 즉, imbalanced dataset으로 학습된 모델이 일반적인 균형을 지닌 test criterion을 갖는 것이 어렵다는 말입니다. 이러한 문제점은 semi-supervised learning에서 더 문제가 되는데, 이는 psuedo label을 모델의 편향된 예측에 기반하여 생성하기 때문입니다. 이러한 문제를 해결하기 위해서 논문에서는 DARP라는 새로운 알고리즘을 제시합니다. DARP는 Distribution Aligning Refinery of Pseudo-label을 의미하며, 분포에 맞춰서 pseudo label을 지정하는 알고리즘입니다.
댓글남기기