
Capsule Networks: 새로운 Deep Learning Network
업데이트:
본문은 해당 링크의 내용을 번역한 글입니다.
Max pooling
Max pooling의 과정에서 활발한 neuron만이 다음 layer로 넘어갈 수 있기 때문에 많은 중요한 정보가 손실된다. Layer 사이에서 위치에 대한 중요한 정보가 사라지는 것이 바로 이 떄문이다. 이러한 문제를 해결하기 위해서 Hinton은 “routing-by-agreement”라는 프로세스를 제안했다. 이것은 손가락, 눈, 입과 같은 low-level의 특징이 high-level의 content에 맞아야 higher level layer에 넘어갈 수 있게 하는 것이다. 만약에 특징이 눈이나 입을 닮았다면 이것은 “얼굴”로 넘어갈 것이고, 만약 input이 손가락이나 손바닥을 포함한다면 “손”으로 보내질 것이다. 이 dymanic routing을 이용하면서 위치의 정보를 특징으로 만들어내는 방식은 2017년 NIPS에서 소개되었다.
paper-link
Capsules
컴퓨터 그래픽에서 렌더링을 통해 물체를 만들어 낼 때, 우리는 컴퓨터에게 어디에 물체를 그려야 하는지, 물체의 크기, 그것의 각도와 같은 공간적인 정보를 제공해야한다. 이런 모든 정보는 화면의 물체로 나타나게 된다. 그렇다면 우리가 이 이미지를 보기만 해도 이러한 정보를 추출해낼수 있다면 어떨까? 이것이 capsule network가 기반하고 있는 방식, inverse rendering이다.
Capsule이 어떻게 공간적인 정보가 제공되지 않는 문제를 해결하는지에 대해서 알아보자.
CNN의 구조를 보면, 우리는 어디서 구조적인 문제점이 발생하는 지를 확인할 수 있다. 아래 사진을 보자.

위 사진은 얼굴을 만들기 위해 필요한 요소들을 모두 가지고 있을 지라도 올바른 얼굴 사진 처럼 보이지는 않는다. 우리는 이것이 얼굴이 가져야할 올바른 모양이 아니라는 걸 알고 있다. 하지만, CNN은 이미지의 위치는 신경쓰지 않고, 특징만을 추출해서 판단하기에 그들이 올바른 얼굴 사진과 위의 잘못된 얼굴 사진 사이의 차이점을 알 수 없다.
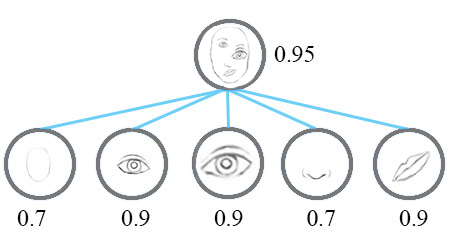
Capsule network는 이러한 문제점을 공간적인 정보와 물체가 존재할 확률에 대한 정보를 encode하는 여러개의 neuron을 구현하여 해결하고자 했다. Capsule vector의 길이는 이미지에서 해당 특징이 존재할 확률, vector의 방향은 위치의 정보를 나타낸다.
A capsule is a group of neurons whose activity vector represents the instantiation parameters of a specific type of entity such as an object or an object part. We use the length of the activity vector to represent the probability that the entity exists and its orientation to represent the instantiation parameters. … 생략 - [source]
디자인과 랜더링 같은 컴퓨터 그래픽스 응용 분야에서 물체는 주어진 몇몇 종류의 매개변수를 이용한 rendering을 통해 만들어진다. 하지만, capsule network에서는 이것과 반대의 방식으로 작용하는데, network가 이미지를 반대로 render하고자 한다. 이미지를 보면서 instantiation parameter가 무엇인지 예측하고자 한다.
이것은 감지해냈다고 생각한 물체를 만들어내고 그것을 label된 training data와 비교하여 예측하는 법을 배운다. 이 과정을 반복함으로서 모델은 instantiation parameter를 더 잘 예측하게 된다. Geoffrey Hinton이 작성한 “Dynamic Routing Between Capsule”에서는 한가지가 아닌 두가지의 loss function을 이용할 것을 제시하였다.
이 논문의 주요 발상은 capsule 사이의 equivariance를 만들어내는 것이다. 이것은 이미지에서 특징을 움직일 때 capsule에서의 존재의 확률은 변화하지 않지만, vector 표현은 바뀐다는 것을 의미한다. Lower level capsule이 특징을 찾아내는 것을 완료한다면, 이 정보는 알맞은 higher level capsule로 넘어가게 된다.
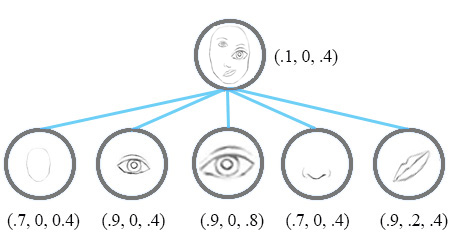
위의 이미지에서 보여지는 것 처럼 모든 특징의 pose 매개변수는 최종 결과값을 결정하기 위해서 사용된다.
Capsule을 이용한 Operation
우리가 이미 알듯이 전통적인 neural net의 neuron은 아래의 scalar operation을 따른다:
- weighting of input
- sum of weighted inputs
- nonlinearity
이 operation은 capsule에서 살짝 바뀌며, 아래와 같이 동작한다
- input vector와 weight matrices간의 행렬 곱셈. 이것은 이미지에서 low-level 특징과 high-level 특징 사이의 아주 중요한 공간적인 관계를 encode한다.
- weighting input vectors. 이 가중치들은 현재 capsule이 어떤 higher-level capsule로 보내질지를 결정한다. 이것은 dynamic routing의 과정을 거쳐서 행해진다.
- sum of weighted inputs. (특별한 점 없음)
- “Squash” 함수를 이용한 nonlinearity. 이 함수는 vector를 가져가서 방향은 보존하고, 길이는 0 이상 1 이하의 값을 갖도록 변형한다.
Capsule 사이의 Dynamic Routing
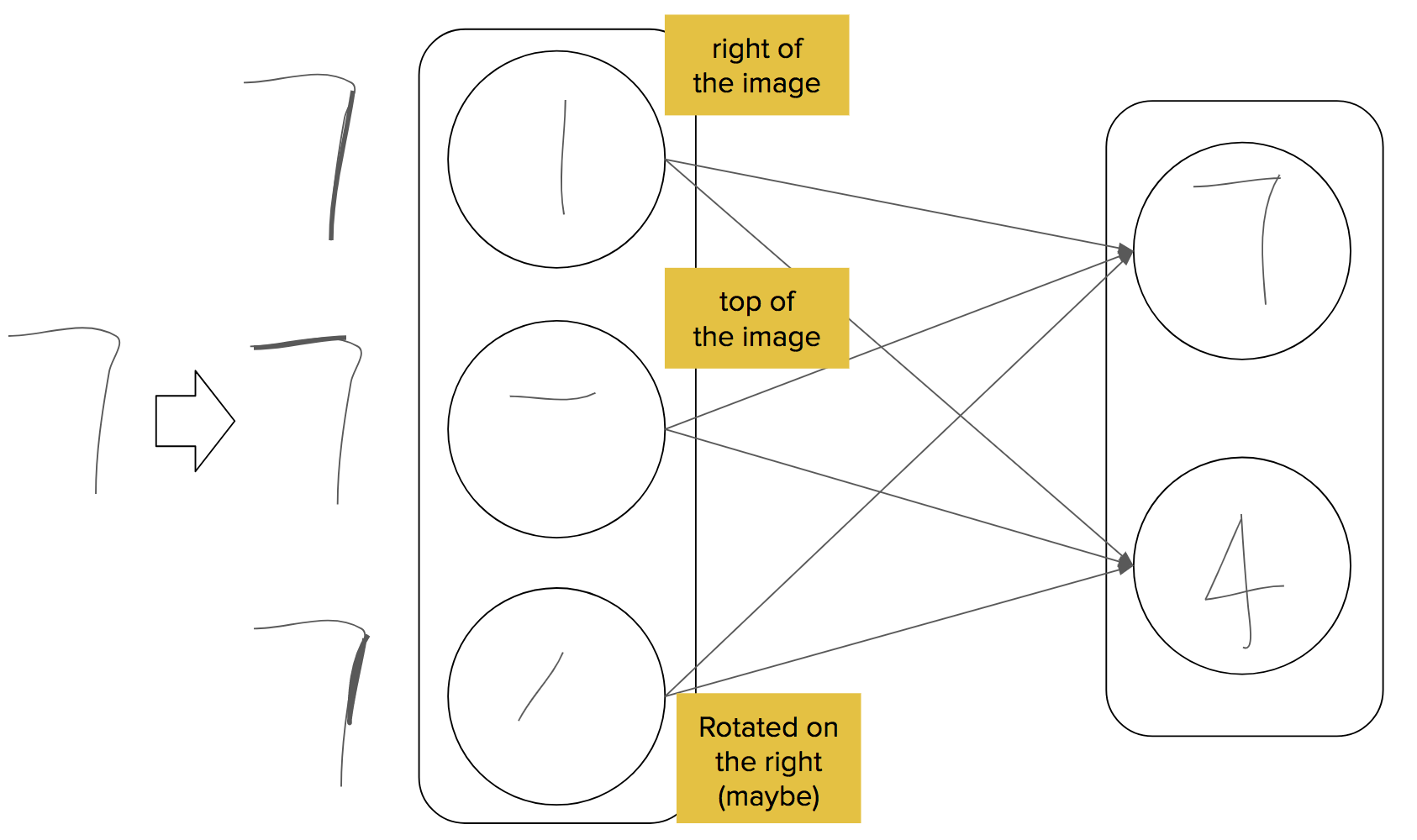
이 routing의 과정에서 lower level capsule은 입력된 input을 input에 대해 동의가 된 higher level capsule로 보낸다. 전송 받을 수 있는 각각의 high level capsule에서 lower capsule은 자신의 output과 weight matrix를 곱해서 예측값을 계산해낸다. 만약 prediction vector가 higher capsule이 가능한 output값을 갖는 큰 스칼라 곱을 갖는다면, high-level capsule에 대한 연결 계수를 증가시키고, 다른 것에 대해서는 감소시키는 top-down 피드백이 있다.
MNIST에서의 Capsule Network의 구조
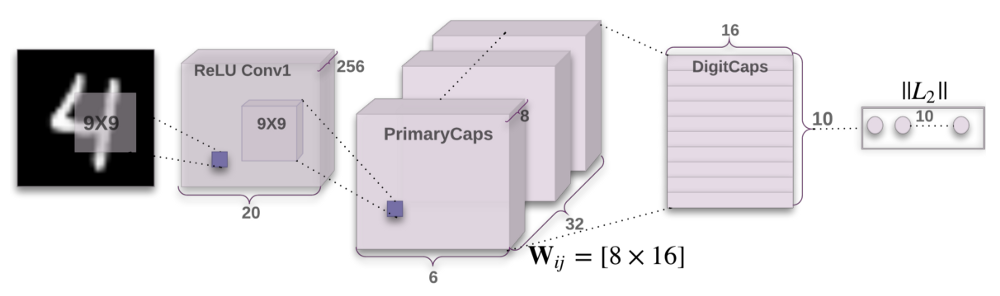
Encoder
Encoder는 이미지 input을 가져가서 이미지를 render하기 위해서 필요한 정보를 모두 포함하는 16차원 vector로 만드는 법을 학습한다.
- Conv-layer: capsule에 의해 분석될 특징을 추출한다. 논문에서는 991 크기의 256개의 kernel을 포함한다고 제시되어있다.
- Primary(Lower) Capsule Layer: 이 layer는 이전에 계속 언급하던 lower level capsule layer이다. 이것은 32개의 다른 capsule을 포함하며 각각의 capsule은 8개의 99256 convolutional kernel들을 이전 convolutional layer의 결과값에 적용하여 4D vector output을 만들어낸다.
- Digit(Higher) Capsule Layer: 이 layer는 이전에 계속 언급된 primary capsule이 (dynamic routing을 이용하여)보내지는 higher level capsule layer이다. 이 layer는 16차원 vector를 만들어내며 object를 다시 만들기 위해 필요한 모든 instantiation parameter를 포함하고 있다.
Decoder
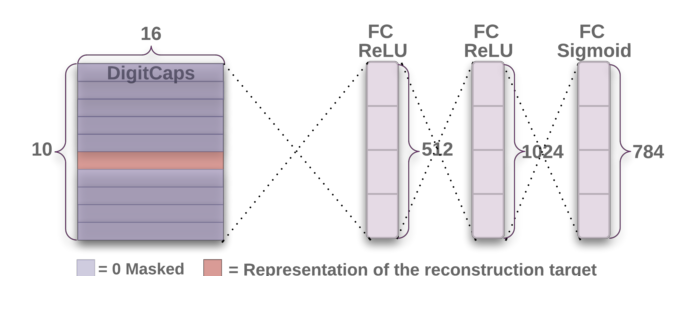
Decoder는 Digit Capsule에서 나온 16D vector를 가져가 어떻게 주어진 instantiation parameter를 이것이 탐색하고 있는 물체의 이미지로 부터 decode할지를 학습한다. Decoder는 Euclidean distance loss function을 이용하여 재구성된 특징이 실제 특징과 비교하여, 얼마나 비슷한지를 결정한다. Capsule은 vector 안에서 digit을 인식하는데에 도움이 될 정보들만을 저장한다는 것을 명심하라. 이 decoder는 아래에 설명된 정말 간단한 feed-forward neural net이다.
- Fully Connected (Dense) Layer 1
- Fully Connected (Dense) Layer 2
- Fully Connected (Dense) Layer 3 — Final Output with 10 classes
왜 capsule network를 사용하지 않는가
CapsNet이 MNIST처럼 간단한 dataset에서 최신의 기술이 된 반면, 이것은 CIFAR-10이나 Imagenet과 같은 데이터 셋에서 어려움을 겪고 있다. 이것은 이미지에서 찾아진 초과된 정보의 양이 capsule을 던져버리기 때문이다.
Capsule net은 여전히 연구와 발전 중에 있으며 몇몇 증명된 결과로 보았을 때 상업적 용도로 사용되기에는 안정적이지 않다. 하지만, 그 concept은 괜찮으며 이 영역에서의 더 많은 발전은 deep learning image recognition 분야에서의 표준화로 이끌 수 있을 것이다.
댓글남기기