
[논문] A Branching and Merging Convolutional Network with Homogeneous Filter Capsules
업데이트:
[2020-02-26 기준] MNIST 정확도 1위인 model의 논문입니다
1. Introduction and Related Work
- 이 paper는 3가지의 분류를 만들어내는 network design을 소개하고, 먼저 결정된 weight와 backpropagation을 통해서 학습한 weight를 합친다.
- 최근 Capsule[7]은 MNIST에서 아주 높은 정확도를 보이면서 활발한 연구 분야가 되었다.
- routing 알고리즘을 이용하여 이전 layer의 capsule이 다음 layer의 어디로 가야할지를 결정한다. 이는 [8]에서 기존의 방식보다 더 확장된 실험을 소개한다.
- [9]에서는 routing 방식 없이 capsule 사이의 element-wise 곱셈을 이용하는 capsule network를 소개한다.
- 이 paper에서는 homogeneous vector capsule이 MNIST 분류에 적용된 네트워트 디자인과 실험을 자세하게 소개할 것이다.
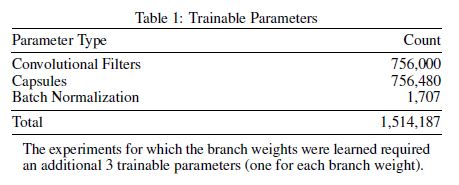
- single model: 99.79% (parameter와 epoch의 수는 75% 감소)
- ensemble model: 99.84%
- 여태까지 대부분의 MNIST classification에 대한 결과들은 data agumentation을 이용하였다.
- network design의 경우, 이미지 회전과 같은 transformation과 같은 data augmentation을 얼마나 효율적으로 하는가에 집중했다.
2. Proposed Network Design
- pooling operation의 사용을 의도적으로 피했다. [16]에서 처럼, pooling이 버리는 information들이 생기기 때문에 사용하기를 피해야한다.
- Max pooling은 데이터를 down-sample하기 위한 방법인데, 현재 MNIST 정도의 데이터는 굳이 down-sample하지 않아도 연산이 충분히 가능하다.
- down-sample을 하지 않으면서, network를 타고 내려갈 수 록 차원을 어떻게 축소해야하는지의 문제점에 직면하게 된다.
- 이것은 convolution operation을 zero-pad하지 않고, 각 convolution operation이 자연스럽게 차원을 가로, 세로 차원에서 2씩 줄여나가며 해결하는 것이 가능하다. (zero-pad는 원래의 sample에서 존재하지 않는 추가하기 때문)
- 위의 사안들을 고려하여 두가지 독창적인 방법을 사용하고자 한다.
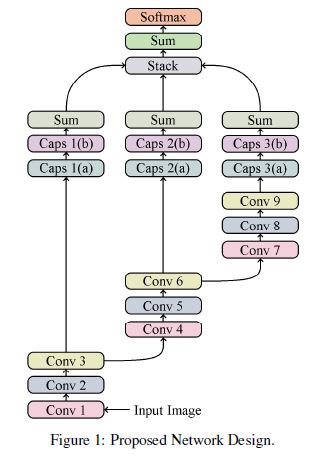
- 한개의 단일된 design보단 여러개의 브랜치를 만든다. 결과적으로 3개의 브랜치를 얻는다. (뒤의 이미지 참조)
- 각각의 브랜치에서 convolution의 output을 scalar neuron으로 줄이기 보단 각각의 filter를 homogeneous vector capsule의 쌍의 첫번째 capsule을 만들기 위한 vector로 바꿨다. 그 다음 element-wise multiplication을 각각의 벡터에 대해서 시행하면, n*m개의 weight vector가 나오며 n은 capsule의 개수 m은 class의 개수이다.
- 분류하기 전에 우리는 3개의 branch-level 상태의 logit을 하나의 class에만 속하도록 만들어야 한다. 이를 우리는 길이가 3인 vector로 branch-level의 logit들을 쌓는 것이다. 그 다음 각각의 vector를 single value로 합산을 통해서 줄였다.
- weight decay regularization이나 어떠한 형태의 dropout regularization을 사용하지 않았다.
- “heavy” weight나 co-adapted-weight가 poor generalization을 유발한다 생각했기 때문이다.
- 의도적으로 routing algorithm을 남겨 놓았다.
- 전통적인 train가능한 weight와 back-propagation의 사용을 선호하기 때문이다.
- 전통적인 train가능한 weight와 back-propagation의 사용을 선호하기 때문이다.
3. Experimental Setup
3.1 Merge Strategies
미리 정해진 weight과 backpropagation을 통해서 학습되는 weight간의 차이를 비교하기 위해서 각각의 방법을 32번씩 시도해서 실험을 하고자 한다.
- Not learnable: 이 실험에서는 세개의 branch에 한 branch가 다른 것에 비해 impact를 더 얻는 것을 막기 위해 동등한 가중치를 부과한다.
- Learn with randomly initialized branch weights(Random Init.): 이 실험에서는 weight가 back-propagation을 통해서 학습하는 것을 허용한다. 3가지의 train가능한 parameter를 Glorot uniform distribution을 통해서 초기화 한다.
- Learnable with branch weights initialized to one(Ones Init.): 이 실험에서는 weight가 back-propagation을 통해서 학습하는 것을 허용한다. 2와의 차이점은 weight를 1로 초기화한다. 이 실험은 random weight에서 시작하는 것과 동등하게 주어진 weight로 시작하는 것의 차이를 이해하기 위해서 행해졌다.
3.2 Data Augmentation
MNIST는 다른 training에 비해서 상대적으로 적은 training image를 갖고 있다. 그래서 주어진 모델의 높은 generalizability를 위해 적절한 data augementation이 요구된다.
- Rotation: 무작위로 선택된 training image를 30도씩 돌린다.
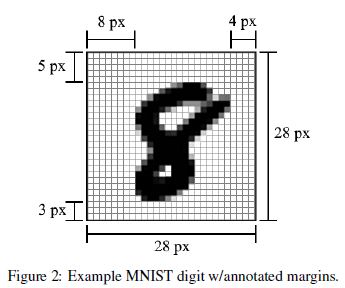
- Translation: 예를 들어서 아래 이미지에서 8에 해당하는 부분을 상하좌우로 움직인다.
- Width: image의 크기를 무작위로 조정한다.
- Random Erasure: 중간의 20*20 pixel의 영역에서 무작위로 선택된 4*4grid 영역을 지운다.
3.3 Training
[9]에서 저자는 HVCs가 cnn에서의 adaptive gradient descent의 사용을 가능하게 했다는 것을 보여준다. 우리는 그들이 사용한 training 기법을 따르며 Adam Optimizer를 이용하고 base learning rate는 0.001로 default/recommended parameter 값을 이용했다. 또한 [9]와 [7]에서 기하급수적으로 base learning rate를 붕괴시켰다.
이 논문의 실험에서는 epoch 300, decay rate는 epoch당 0.98로 설정하여 overfitting 없이 실험을 진행할 수 있었다. Test의 경우에서는 decay rate를 0.999로 설정한다.
4. Experimental Results
4.1 Individual Models
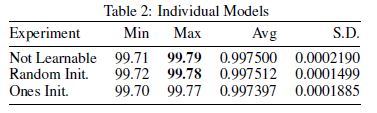
- 3개의 실험에 대해서 각각 32번씩 시도를 하였다. 결과적으로 training은 loss surface에서 다른 방향으로 나아갔다.
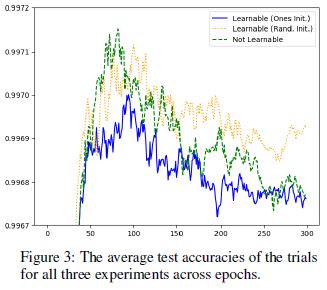
- 3개의 실험의 결과값은 큰 차이를 보이지 않았지만, non-learnable branch하고 equal branch weight를 지닌 실험은 1로 learnable branch를 초기화 한 실험보다 모든 epoch에서 정확도가 높았다.
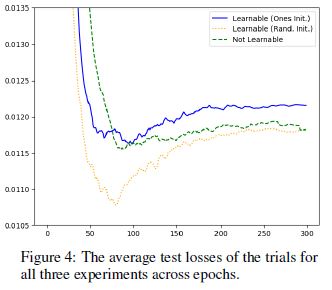
- 추가적으로 learnable branch를 무작위로 초기화한 실험은 모든 epoch에서 두 실험에 비해 낮은 loss값을 지녔다.
4.2 Ensembles
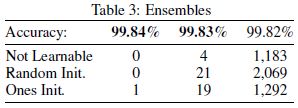
- 여러 모델을 기반으로 다수가 예측값에 투표를 하는 방식이다. 이 방식은 individual model의 정확도를 상회한다.
4.3 Branch Weights
각 branch에 대한 weight가 어떻게 변화했는지를 관찰할 수 있다.
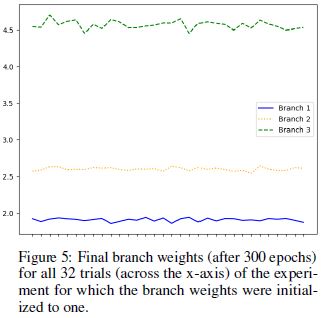
- 32번의 trial에 대한 branch weight를 1로 초기화했을 때의 최종 branch weight이다.
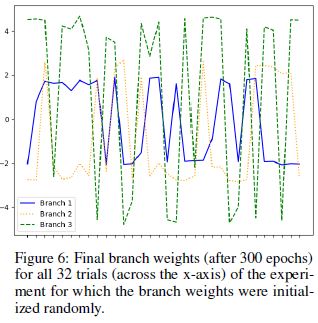
- 32번의 trial에 대한 branch weight를 무작위로 초기화했을 때의 최종 branch weight이다.
4.4 Troublesome Digits
총 96번의 시도에서 10,000개의 샘플에 대해서 9,907개의 동의가 있었다. 48개는 모든 96개의 시도중에서 잘못 분류되는 경우가 더 많았다, 반면 오직 21개만이 한 실험의 32개의 trial를 거치지 않고 더 자주 잘못 분류되었다. 이를 통해서 비슷한 정확도를 지니더라고 각 실험해서의 다른 merge strategy가 분류에 지대한 영향을 끼친다는 것을 확인할 수 있었다.

96번의 시도에서 4개의 sample만이 모든 모델에서 잘못 분류되었다. 1901, 2130, 2293과 6576이다. Not learnable은 3422번을 단 한번도 올바르게 판단한 적이 없다. Random init은 2597번을 올바르게 판단한 적이 없다. Ones init은 2597과 3422를 올바르게 판단한 적이 없다.
4.5 MNIST State of the Art

- 과거의 최신 MNIST 모델의 결과값을 소개한다.
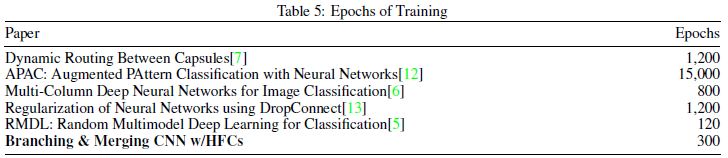
- table 4에서 소개된 모델들이 몇 epoch을 돌렸는지를 비교한다.
5. Conclusion
이 논문에서는 간단한 CNN을 소개하고 모델을 위한 규율과 기저를 소개했다. 또한, 3가지 다른 방식의 merging 방법을 소개하여 각각의 방식을 비교했고 ensemble의 방식은 새로운 뛰어난 결과를 도출한다는 것을 확인할 수 있었다. 비록, branch weight의 초기값을 1로 설정한 모델이 가장 높은 정확도를 보였지만 무작위로 초기화된 실험이 가장 많은 ensemble을 생산했다.
네트워크 구조 말고도, 이 논문은 robust하고 domain specific한 data augmentation을 제시하여 더 많은 종류의 digit의 rendering을 노렸다.
댓글남기기