
[논문] M2m: Imbalanced Classification via Major-to-minor Translation
업데이트:
1. Introduction
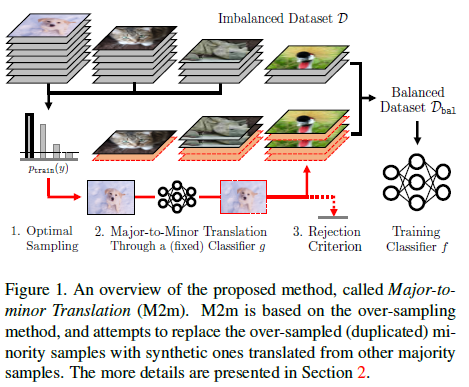
이 논문은 2020년 CVPR에서 발표된 M2m: Imbalanced Classification via Major-to-minor Translation입니다. Class imbalance 문제에 대해서 다룬 논문이며, 이 문제를 논문에서 re-sampling을 이용하여 해결하고자 합니다. 일반적으로 imbalance 문제를 해결하기 위해서는 re-weighting이나 re-sampling 같은 방식을 많이 활용하는데, 이 논문에서는 majority class의 데이터를 minority class 데이터로 변형하여 minority class를 up-sampling하는 방식을 이용습니다. 실험 결과도 여러 데이터 셋에 대해서 기존의 re-sampling이나 re-weighting 방식보다 성능이 향상된다는 것을 보여주었습니다.
논문에서 말하는 주요 기여는 다음과 같습니다.
- Translating majority sample into synthetic minority sample, while not affecting the performance of majority class.
- Designed simple rejection criterion.
- Suggested an optimal distribution for sampling majority seed to be translated in generation process.
2. M2m: Major-to-minor translation
- \(\mathcal{D} = \{(x_{i}, y_{i})\}^{N}_{i=1}\): imbalanced 데이터 셋
- \(K\): class 수
- \(x \in \mathbb{R}^{d}, y \in \{1, \cdots, K\}\): input과 class label
- \(f : \mathbb{R}^{d} \rightarrow \mathbb{R}^{K}\): classifier designed to \(K\) logits
- \(N := \Sigma_{k}N_{k}\): label이 K인 데이터의 수
주어진 변수가 다음과 같을 때, 논문에서 제시하는 문제 상황은 \(N_{1} \geq N_{2} \geq \cdots \geq N_{K}\) 입니다. (class data imbalance) 이런 상황에서 train 데이터와 test 데이터의 분포가 같다고 가정된 채로 모델이 학습되지만 실제로는 그렇지 않습니다. Class-imbalance learning의 목표는 train 데이터의 분포로부터 \(f\)를 잘 학습시켜 standard training보다 test 데이터의 분포에 더 일반화 되는 것입니다.
Intuition: Adversarial Perturbation
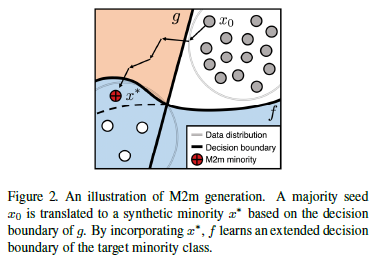
이 논문은 “Major-to-minor Translation”을 사용하여 새로운 균형잡힌 데이터 셋 \(\mathcal{D}_{bal}\)을 만들어냅니다. 이는 \(\mathcal{D}\)에 pretrain 되어있는 baseline classifier \(g\)에 대해서 adversarial perturbation이 된 이미지를 만들어 \(f\)를 학습하는데 이용하는 것입니다. Figure 2처럼 \(g\)의 경계를 기준으로 \(x_{0}\)를 \(x_{*}\)로 만들어 minority 학습 데이터를 늘리는 방식입니다. 이렇게 생성된 데이터를 이용하여 학습된 classifier \(f\)는 overfitting 되지 않고 imbalanced data에 대해서 좋은 성능을 보일 수 있습니다. 이런 결과가 관찰되는 이유는 Adversarial Examples Are Not Bugs, They Are Features와 비슷한 이유일 것이라 추측합니다.
새로운 균형잡힌 데이터 셋 \(\mathcal{D}_{\rm bal}\)을 위해 생성되는 \(x^{*}\) 수식은 아래와 같습니다.
- \(\mathcal{L}\): cross entropy loss
- \(\lambda\): hyperparameter, sample이 \(k\)로 레이블 될 확률을 줄여줌
저자들은 이런 counter-intuitive-effectiveness가 발생하는 이유에 대해서 두가지를 가설로 세웁니다: (1) majority dataset 예제의 다양성이 minority의 overfitting을 막기 위해 활용된다 (2) 다른 classifier \(g\)는 minority dataset의 특징을 잡기에 충분하다. 이러한 관점에서 adversarial example은 minority class의 일반화를 향상시키기 위해 좋은 방법이며, 완벽한 대체는 아니지만 기존의 standard augmentation보다 상당히 효과적이라 할 수 있다 말합니다.
Rejection Criterion
Adversarial perturbation이 효과적인 augmentation이지만, 모든 majority class의 데이터를 perturbation을 가해서 minority class로 \(f\)를 학습시키면 되는 것은 아닙니다. M2m 기법을 이용하여 생성된 데이터들이 오히려 \(f\)의 성능을 저하시킬 수 있기 때문입니다. 그래서 이러한 synthetic example들이 성능의 저하를 불러일으키는 위험을 방지하기 위해 rejection criterion을 지정합니다.
- \(k_{0}\): original class
- \((\cdot)^{+} := {\rm max}(\cdot, 0)\): 점의 내용과 0중 더 큰 값
- \(\beta \in [0, 1)\): \(g\)에 대한 의존성을 조절하는 hyperparamter로 \(\beta\)가 작을수록 \(g\)에 대한 의존성이 크다. \(\beta\)가 작을수록 M2m으로 만들어진 데이터의 개수가 많다.
이를 통해서 몇개의 sample을 이용해야 효과적인지를 설계하며, reject된 synthetic sample의 경우에는 기존의 minority sample로 대체합니다. 생성되는 데이터의 개수 외에도, 변형할 데이터를 선택하는 기준이 있습니다. 이를 optimal seed sampling이라 하며, 앞서 제안된 rejection criterion을 기반으로 target class \(k\)로 바꿀 \(k_{0}\)를 가진 데이터 \(x_{0}\)를 선택할 sampling distribution \(Q(k_{0} \| k)\)를 설계합니다. \(Q\)는 선택된 데이터가 \(k\)로 바뀔 확률을 최대화하며 최대한 다양한 class를 선택하도록 합니다. 이를 식으로 표현하면 아래의 최적화 식과 같아집니다.
\[\underset{Q}{\rm max} [\mathbb{E}_{Q}[\log P_{\rm accept}]+H(Q)]\]\(Q=P_{\rm accept}\)가 이 최적화 문제의 답이기 때문에 rejection 확률에 따라서 \(Q(k_{0} \| k) \propto 1 - \beta^{(N_{k_{0}}-N_{k})^{+}}\)입니다. \(k_{0}\)가 선택된다면, \(x_{0}\)는 랜덤으로 균등하게 sample되며 M2m의 over-sampling 알고리즘은 아래와 같습니다.

3. Experiments
이 논문은 vision외에도 nlp 데이터 셋에 대해서도 실험을 진행했습니다. 또 imbalance dataset만이 아닌 balanced dataset에 대한 성능도 측정하기 위해서 balanced accuracy(bACC)와 geometric means scores(GM)을 metric으로 이용하였습니다. 실험에 사용된 모델로 CIFAR-10/1000, ImageNet-LT, CelebA에는 ResNet-32, SUN397에는 ResNet-18을 이용하였으며 Twitter, Reuters에는 2-layer fully-connected network를 이용하였습니다. Adversarial perturb를 위한 classifier \(g\)는 모두 같은 조건으로 만들어진 모델을 이용하였습니다.
Datasets
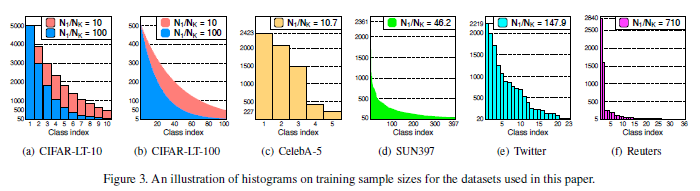
위의 이미지는 각 데이터셋들의 불균형 정도를 보여줍니다. \(N_{1}/N_{k}\)가 커질수록 불균형의 정도가 심해집니다. 각 데이터셋에 대한 자세한 설명은 논문에 소개되어있습니다.
- Standard vision dataset: CIFAR-10/1000, ImageNet-LT
- Real world imbalanced dataset: CelebA, SUN397
- NLP dataset: Twitter, Reuters
Baseline methods
Different loss functions
- Empirical Risk Minimization (ERM): training on cross-entropy without any re-balancing
- Focal loss (Focal): the objective is upweighted for relatively hard examples to focus more on the minority
- Label-distribution-aware margin (LDAM): the classifier is trained to impose larger margin to minority classes
Re-sampling
- Re-sampling (RS): balancing the objective from different sampling probability for each sample
- SMOTE: a variant of re-sampling with data augmentation
- Deferred re-sampling (DRS): re-sampling is deferred until the later stage of the training
Re-weighting
- Re-weighting (RW): balancing the objective from different weights on the sample-wise loss
- Class-balanced re-weighting (CB-RW): a variant of re-weighting that uses the inverse of effective number for each class, defined as \((1-\beta^{N_{k}})/(1-\beta)\). (\(\beta=0.9999\))
- Deferred re-weighting (DRW): reweighting is deferred until the later stage of the training, repsectively
Results
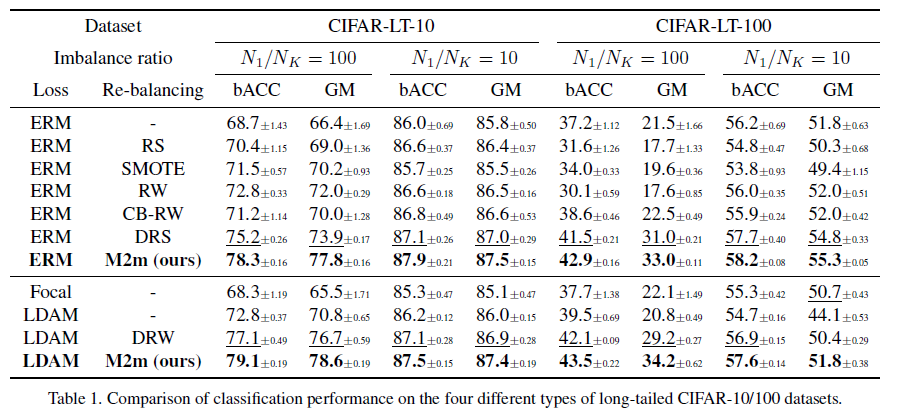
이 표는 CIFAR-10/100에 대한 결과값입니다. \(N_{1}/N_{k}\)가 10일때, 100일때에 대해서 실험을 진행했으며 앞서 소개된 baseline method와 비교하였을때, M2m이 가장 좋은 성능을 보이고 있음을 확인할 수 있습니다. Loss function을 ERM 또는 LDAM를 사용해도 balanced accuracy와 geometric means scores 모두 M2m이 가장 성능을 보였습니다.
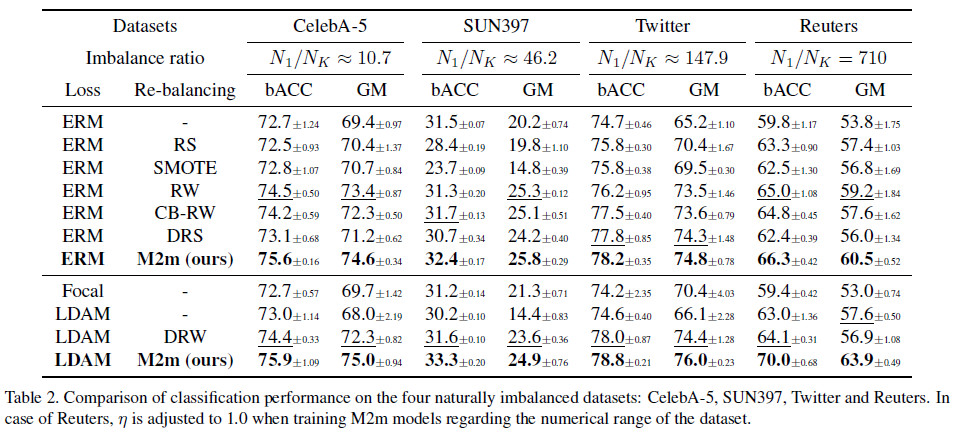
이 표는 Real-world 데이터에 대해서 나온 결과값인데, 이 경우도 standard dataset과 마찬가지로 M2m이 가장 좋은 성능을 보이고 있음을 확인할 수 있습니다.
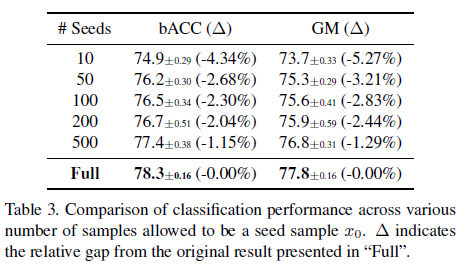
이 표는 seed sample이 된 갯수에 따른 모델의 성능을 비교한 표입니다. 이 표는 seed sample이 늘어남에 따라 minority sampel의 다양성이 증가함을 보여주며, 이는 M2m이 majority class의 다양성을 minority의 overfitting을 막는데에 이용되고 있음을 보여줍니다.
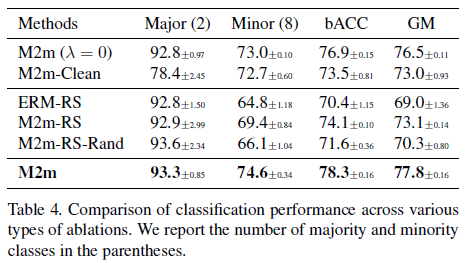
앞서 M2m을 만드는 단계에서 최적화 식을 소개했었습니다. 논문에서 \(\lambda \cdot f_{k_{0}}\)을 synthetic sample의 질을 향상시키기 위해서 이용한다 제시했었는데, 이 표는 그러한 제약사항들이 실제 효과가 있는지에 대해서 보여줍니다.
- M2m (\(\lambda=0\)): M2m에서 \(\lambda\)를 0으로 설정하고 실험
- M2m-Clean: sample seed로 선택된 \(x_{0}\)를 synthetic sample로 넣지 않고 실험
- ERM-RS: ERM으로 학습하고 ablation(제약조건)없이 re-sampling을 이용
- M2m-RS: M2m을 ablation없이 이용하였으며, ablation이 없는 경우
- M2m-RS-Rand: 생성된 synthetic sample의 label을 target class가 아닌 랜덤 label을 부여한 경우
- M2m: 논문에서 제시한 standard M2m
이 표의 결과를 통해서 ERM과 M2m을 비교했을때의 우수함, adversarial sample의 유효성, ablation의 유효성에 대해서 검증하였음을 볼 수 있었습니다.
4. Conclusion
이 논문은 over-sampling의 새로운 기법 M2m translation을 제시하였으며, adversarial example과 imbalanced learning의 새로운 연구방향을 제시함에 있어서 그 의의를 갖는다 말하고 있습니다.
댓글남기기