
[논문] A New Defense Against Adversarial Images: Turning a Weakness into a Strength
업데이트:
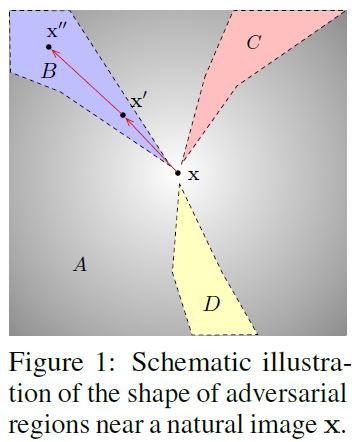
Introduction
- 최근의 연구는 adversarial perturbation이 고차원의 공간에서의 natural data 분포의 내재된 특성일수도 있다는 것을 보여준다.
- 하지만 여기서는 그 내재된 특성의 존재를 data가 perturb되지 않았다는 것의 증명이라는 새로운 접근을 한다.
- Natural image의 모순되어 보이는 두가지 특징을 이용한다.
- Gaussian noise를 추가한 뒤 prediction의 변화를 관찰함으로써 random noise에 대한 robustness를 측정한다.
- Input image의 label을 바꾸게 할 때 까지 몇번의 gradient step이 필요한지를 관찰하여 decision boundary에 대한 근접도를 측정한다.
- 이때, perturbed image들이 이 두개 중 적어도 하나의 조건을 위반했다고 가정한다.
Background
Attack Overview
- Test의 방식은 black-box setting과 white-box setting 두가지로 나뉠 수 있다.
- 여기서는 white-box setting을 이용하여 test를 진행한다.
-
_{y’}=p(y’ \mathbf{x}))
- target image
가 주어졌을 때,
를 올바르게 분류한다면 attacker는 이 최적화 문제를 해결해야한다.
- 이 최적화 문제는 untargeted attack을 정의한다.
- 대조적으로 targeted attack에서는
인 target label이 주어지고, target label로의 분류를 지향하기 때문에 수식이 아래와 같아진다.
Optimization
- adversarial loss function을 무엇을 사용하느냐에 따라서 targeted attack은 바뀐다.
- white-box (untargeted) attack에서 최적화된 margin loss는 아래와 같다.
Enforcing perceptibility constraint
- perceptibility의 측정을 위해서 attacker는
- adversarial loss에 Lagrangian penalty로 constraint를 접는다.
- 실현가능한 구역 쪽으로 모든 iteration의 끝에 projection step을 적용한다.
- Euclidean Norm이 미분가능하기 때문에 아래와 같이 강화되곤 한다.
는 모든 좌표의
의 차이를 매 gradient step마다
로 제한하여 강화가 가능하다.
Detection Methods and Their Insufficiency
Detections
- Feature Squeezing
- image content를 바꾸지 않는 transformation(median smoothing, bit quantization)등을 가한다.
- model은 이런 변화가 이미지에 가해지면 비슷한 prediction을 예측한다.
- 여기서 maximum
을 측정하고 이 값이 threshold보다 크다면 adversarial image임을 판단한다.
- image content를 바꾸지 않는 transformation(median smoothing, bit quantization)등을 가한다.
- Artifacts
- input density와 model uncertainty를 adversarial image의 특징을 잡기 위해서 사용한다.
- input density: feature vector의 kernel density estimation으로 측정
- model uncertainty: 무작위의 dropout mask를 이용해서 model의 network를 평가하고 output의 variance를 계산, dropout의 Bayesian interpretation을 이용하여 model의 uncertainty를 측정
- adversarial input은 낮은 density와 높은 uncertainty를 가졌다.
- input density와 model uncertainty를 adversarial image의 특징을 잡기 위해서 사용한다.
- 여러 기준의 Detector
- 기준을 합칠 수 있다.
- 여러개의 method 중에서 하나만 fail 해도 모두 fail
- input을 분류하기 위해서 가장 top 분류기를 특징으로 train한다
- Adversarial image를 탐지하는데에 또 다른 유용한 특징
- 중간 layer에서 추출된 convolutinal 특징
- 픽셀공간에서 training sample까지 거리
- non-maximal class probability의 entropy
- 기준을 합칠 수 있다.
Insufficiency
- Detection 우회
- bit-quantization 같은 미분 불가능한 component는 backward pass를 통해서 예측 가능
- randomization은 Monte Carlo sampling을 통해 최소의 값으로 예측된 adversarial loss로 피해갈 수 있다.
Detection by Adversarial Perturbations
Criterion 1: Low density of adversarial perturbation
- Natural image에서 만들어진 CNN에서 추출된 특징들은 비교적 random input으로 붙 robust 하다.
- natural image에 적용된 random perturbation은 predicted label을 바꿔서는 안된다.
- 이 criterion은 주어진 input이 가우시안 noise에 robust한지를 체크한다.
- C1: Robustness to random noise (on pretrained ResNet101, imagenet)
- 만약
가 충분히 크다면 input
- 이미지의 결과는 C1기준을 충족시키지 못한다->successful on black, gray box attacks
- white-box attack에서는 불충분하다
- 충족시키기 위해서는 예상한 adversarial loss를 Monte Carlo 샘플링을 통해서 최적화 시켜야한다. (이 결과값이 x’’)
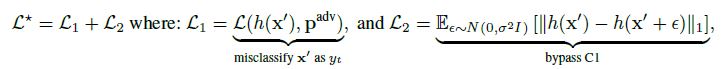
- loss function을 위의 식처럼 바꾼다. 이는 델타 값을 증가시켜서 C1을 써서 탐지하는 것을 더 쉽게 만든다.
- 충족시키기 위해서는 예상한 adversarial loss를 Monte Carlo 샘플링을 통해서 최적화 시켜야한다. (이 결과값이 x’’)
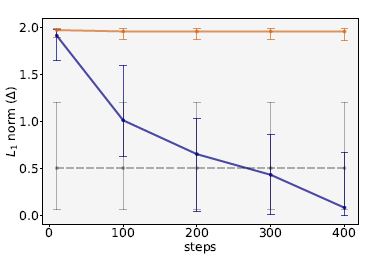
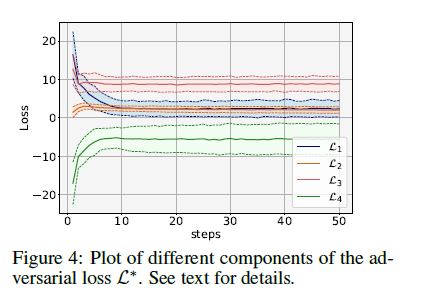
- 최적화한 loss로 step수에 따른 델타값의 변화이다.
Criterion 2: Close proximtiy to decision boundary
- 이미지가 틀린 class의 decision boundary에 가까운지를 확인하는 기준을 정의한다.
- C2(t/u): adversarial noise 민감성
- C2는 targeted attack에 특성화된 C2t와 untargeted attack에 특성화된 C2u로 나뉜다.
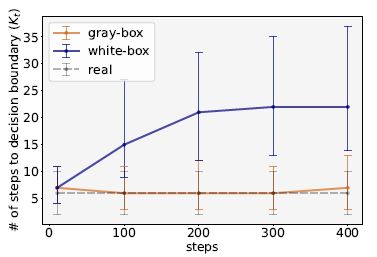
- Decision boundary까지의 step의 수에 따라 adversarial loss를 최적화 한것의 효과를 보여준다.
- 예상했듯이 실제 이미지는 많은 step을 요구하지 않는다.
- Attacker가 기준 C1을 속이기 위해서
의 증가를 불러온다.
- C2는 targeted attack에 특성화된 C2t와 untargeted attack에 특성화된 C2u로 나뉜다.
- C2에서 실제 이미지와 white box의 분리가 C1이 겹치기 시작하는 구간에서 시작되므로 C2t는 C1에 대해서 최적화된 이미지를 detect하기에 효과적이다.
Detection strategy
- C1과 C2를 동시에 만족 시키는 것은 거의 모순적
- 원본의 input에서 decision boundary의 incorrect class까지의 최소 거리가 짧은 동안,
짧은 시간내에 decision boundary까지 이끄는 방향의 density도 낮다.
- 원본의 input에서 decision boundary의 incorrect class까지의 최소 거리가 짧은 동안,
- 두 가지 기준을 사용하는 detection strategy는
를 계산한다.
와 계산된 값을 비교한다.
- 하나라도 충족시키지 못하면 adversarial example로 input이 거부된다.
- 이런 method에 따라서 앞에서의
는 equation3을 따른다. (C1을 우회하기 위함)
를 우회하기 위해서
를 우회하기 위해서
를 모두 합쳐서
를 이용한다.
- total loss는 Adam을 이용하여 최적화한다.
Experiment
마지막 strategy에 기반하여 detection mechanism을 test한다.
Setup
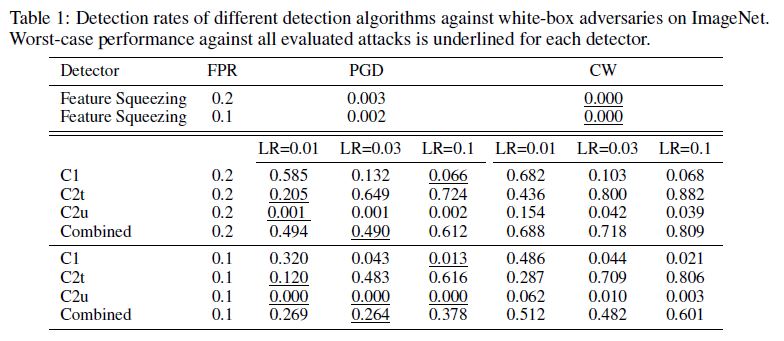
- Pretrained ResNet101 in pytorch, ImageNet
- include detection results using Inception-v3 model
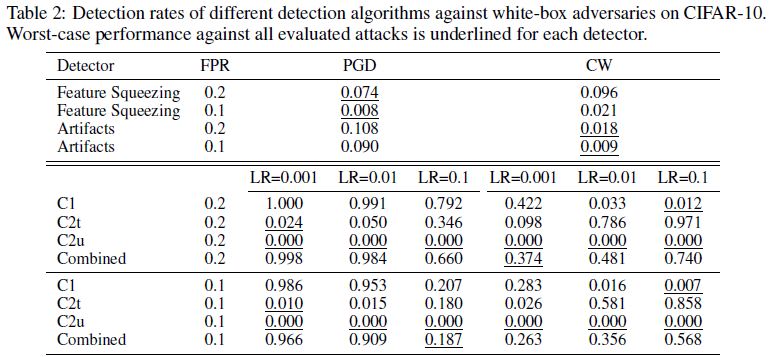
- Train VGG-19 model, dropout rate 0.5, CIFAR-10
Attack algorithm
- 두개의 대표적은 loss function들의 targeted와 untargeted variant를 사용해서 실험한다.
- CW attack에서 정의된 margin loss
- PGD attack의 cross-entropy loss
bound의 경우
로 설정하여 시각적으로도 변화를 알아챌수 있다.

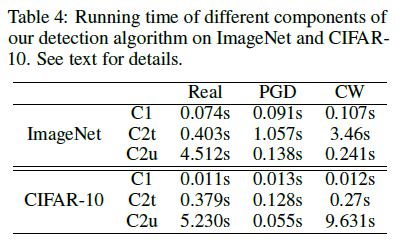
Result
- ImageNet
- CIFAR-10
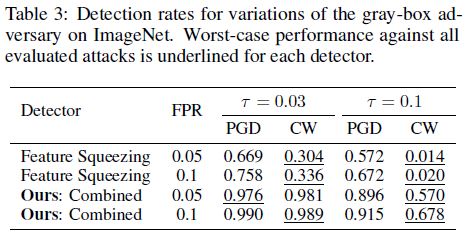
- Gray-box detection results
댓글남기기