
[논문] Are Labels Required for Improving Adversarial Robustness?
업데이트:
1. Introduction
- 눈으로 인식할 수 없는 정도의 변형으로 image classification을 속일 수 있으며 이런 속임을 막기 위한 방법으로 supervised adversarial training이 있다.
- supervised adversarial training: label이 있는 adversarial sample을 만들어서 그 이미지를 training set으로 이용한다.
- unsupervised adversarial training: adversarial training에 unlabeled data를 이용한다.
- Hypothesis: 추가적인 unlabeled example들은 adversarial attack에 robustness하게 만들기 위해서 충분하다.
(section 3, 4.1.2)- 관찰1: adversarial robustness는 natural image에 대한 smoothness에 달려있고, 이것은 unlabeled data에서 estimate될 수 있다.
- 관찰2: 표준 generalization에는 아주 적은양의 데이터만 필요하다.
- 그러므로 만약 adversarial training이 label noise에 robust하다면, supervised example에서 생산된 label은 adversarial robustness를 train하기 위한 unsupervised example로 전파될 수 있다.
- 위의 가설을 기반으로 unlabeled data를 adversarial training에 이용하기 위해서 Unsupervised Adversarial Training을 알아본다.
2. Related Work
Adversarial Robustness
- Adversarial attack에 가장 robust하다 증명된 defense는 adversarial training이다.
- Perurb된 image를 training set으로 사용한다.
- 최근 이런 연구들은 adversarial roubustness의 generalization에는 natural generalization보다 더 많은 data가 필요하다 주장했다.
- 이 논문에서는 label된 data가 더 필요한지, 아니면 unlabel된 data가 충족시킬수 있는지를 연구한다.
Semi-supervised learning
- Unlabel된 data를 이용하여 학습하는 것은 활발한 연구분야이다.
- semi-supervised learning은 더 나은 모델을 학습하기 위해서 label된 데이터에 unlabel된 data를 추가하여 학습하는 방식이다.
- smoothness regularization은 semi-supervised learning의 효과적인 기술중 하나이며 UAT에서도 model 결과값을 smooth하기 위해 adversarial perturbation을 이용한다.
Semi-supervised learning for adversarial robustness
- Label 없이 robustness가 최적화 될 수 있다는 관찰은 아래 3개의 논문에서 만들어졌다.
- Y. Carmon, A. Raghunathan, L. Schmidt, P. Liang, and J. C. Duchi. Unlabeled Data Improves Adversarial Robustness. In NeurIPS, 2019.
- A. Najafi, S.-i. Maeda, M. Koyama, and T. Miyato. Robustness to Adversarial Perturbations in Learning from Incomplete Data. arXiv preprint arXiv:1905.13021, May 2019.
- R. Zhai, T. Cai, D. He, C. Dan, K. He, J. Hopcroft, and L. Wang. Adversarially Robust Generalization Just Requires More Unlabeled Data. arXiv preprint arXiv:1906.00555, Jun 2019.
3. Unsupervised Adversarial Training
Notation & Evaluation
-
=\textup{argmax}{y\in&space;\mathcal{Y}}p{\theta}(y x)) : predictor, maps input x to y
-
): neural network에 의해서 매개화 된다. :
결합 분포를 따르는 data point이다.
- Training set
: labeled training data
: unlabeled training data
- Evaluation
- objective: minimizing adversarial risk
3.1 Unsupervised Adversarial Training (UAT)
- 더 많은 label된 data가 필요한지, unsupervised data로 충분한지에 대해 두가지 방식으로 접근한다.
Strategy 1: Unsupervised Adversarial Training with Online Targets (UAT-OT)
- Adversarial Risk는 아래와 같이 될수 있다.
- 첫번째 term을 classification loss, 두번째 term을 smoothness loss라 한다.
- adversarially train된 모델에서도 smoothness loss가 classification loss를 지배하는 것이 관찰되었기 때문에, smoothness는 label에 의존도가 없으므로 unsupervised data를 통해서 smooth될 수 있다. 이때 사용되는 loss는 아래와 같다.
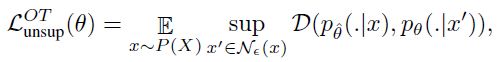
: Kullback-Leibler divergence
Strategy 2: Unsupervised Adversarial Training with Fixed Targets (UAT-FT)
- 이 방법은 standard generalization과 adversarial generalization 사이의 gap을 가중화한다.
을 통해서 base classifier를 만든다. 그리고 이 모델은
의 label을 추측하기 위해서 이용된다.
- 이것은 standard supervised adversarial training을 이용하는 것을 허락하며 아래의 loss를 따른다.
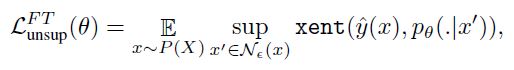
: cross-entropy
:
- 제공된 많은 양의 unlabeled dataset을 통해서 UAT-FT는 base classifier의 smooth된 버전을 회복한다.
Overall training
- 전반적으로 loss에 있어서 hyperparameter에 의해 통제되는 supervised loss와 선택된 unsupervised loss를 이용하였다.
- unsupervised loss는 UAT-OT나 UAT-FT 또는 둘다 될 수 있다.
- unsupervised loss는
를
3.2 Theoretical Model
- Unlabeled data의 영향을 더 잘 이해하기 위해서 아래 논문에 소개된 setting을 사용하였다.

- L. Schmidt, S. Santurkar, D. Tsipras, K. Talwar, and A. Madry. Adversarially Robust Generalization Requires More Data. In NeurIPS, 2018.
- 이 setting은 adversarial generalization이 natural generalization에 비해 더 많은 data를 요한다는 것을 보이기 위해 필요하다.
- 하지만, 같은 adversarial accuracy를 얻기 위해서 알고리즘은 적어도
개의 sample을 필요로 하며
개의 sample을 필요로 하는 알고리즘을 제공하였다. (
는 고정상수이다.)
- Unlabeled data로 labeled sample을 대체하면 sample complexity가 극적으로 개선되는 것을 보여준다.
- UAT-FT의 물리량을 정의한다. Adversarially robust한 classifier를 train하기 위해서 Gaussian model의 알고리즘이 sample mean을 계산한다.

- 이 Theorem은 semi-supervised setting에서
개의 sample을 필요로 한다는 것을 보여준다.

4. Experiment
- Setup
- CIFAR-10과 SVHN dataset에 대해서 실험을 한다.
을
과
로 제한한다.
- Adversarial 평가에는 20-step 반복되는 FGSM을 사용한다.
- 4.2에는 더 강력한 multi-targeted attack을 이용한다. (PGD보다 강력함)
4.1 Adversarial robustness with few labels
Unlabeled data가 labeled example에 비해서 경쟁력이 있는가?
4.1.1 Results
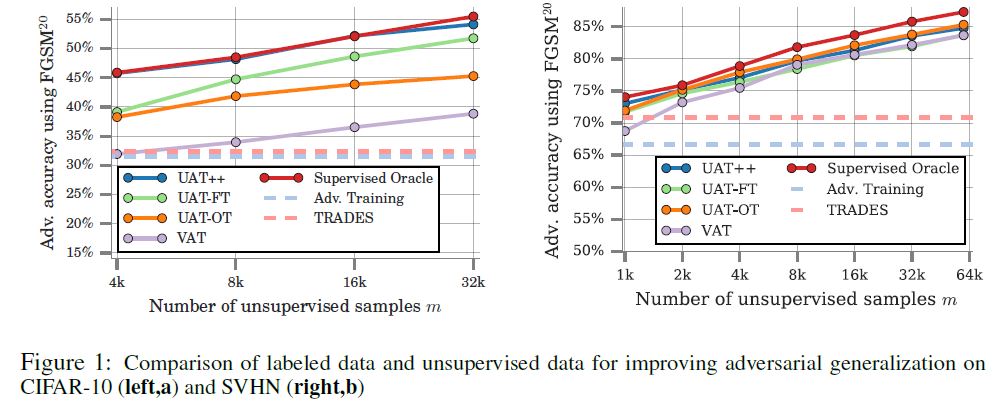
- UAT++, UAT-FT, UAT-OT: paper의 모델
- Supervised Oracle: 전부 label된 데이터를 이용하여 train
- VAT: semi-supervised
- TRADES: unsupervised data를 이용하지 않는다
- 결론
- UAT++가 supervised oracle과 비슷한 adversarial robustness를 얻는다.
4.1.2 Label noise analysis
- Setup
- CIFAR-10을 절반으로 나누고, 첫 20K 예제들은 base classfier train에, 나중 20K 예제들은 UAT model training에 사용한다
- 또 다른 20K개는 4K는 label된 채로, 16K개는 label되지 않은 채로 둔다.
- UAT-FT(correlated)에 대해서는 UAT-FT procedure를 이용하여 psuedo-label을 만들어낸다.
- 결과적으로 7%에서 48% 사이의 에러를 갖는 base classifier를 생산한다.
- UAT-FT(random)에 대해서는 무작위로 선택된 틀린 class에서 무작위로 label을 뒤집는다.
- Result
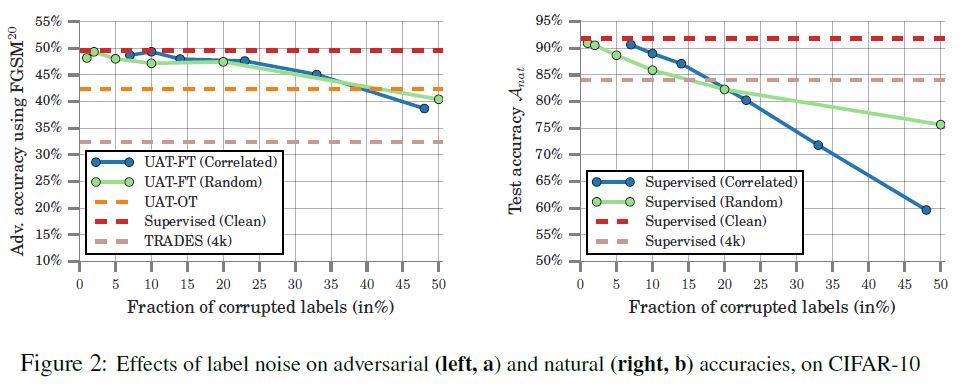
- 결론
- UAT는 base classifier의 오류가 50퍼 임에도 불구하고 8.0% 상승된다는 label noise에 중요한 robustness를 보여준다.
- 결론
4.2 Unsupervised data with distribution shift
UAT를 의 분포를 따르도록 하여 robustness를 관찰한다. 그리고 UAT를 CIFAR-10에 대한 robustness를 증가하도록 사용한다.
(접근 방식이 분포가 바뀌어도 유효한지를 확인하기 위해서 80 million tiny image들을 사용)
- Preprocessing
- 80m의 대부분이 CIFAR-10 클래스들과는 다른 이미지를 포함하기 때문에, 아래 논문에 소개된 automated filtering 기술을 이용한다.
- Q. Xie, Z. Dai, E. Hovy, M.-T. Luong, and Q. V. Le. Unsupervised Data Augmentation. arXiv:1904.12848
- 일단, web query에서 얻어진 CIFAR-10 class와 match된 image로 제한한다.그리고 GIST feature를 이용하여 CIFAR-10과 가까운 복제물들을 제외한다.
- 80m의 대부분이 CIFAR-10 클래스들과는 다른 이미지를 포함하기 때문에, 아래 논문에 소개된 automated filtering 기술을 이용한다.
4.2.1 Preliminary study: Low data regime
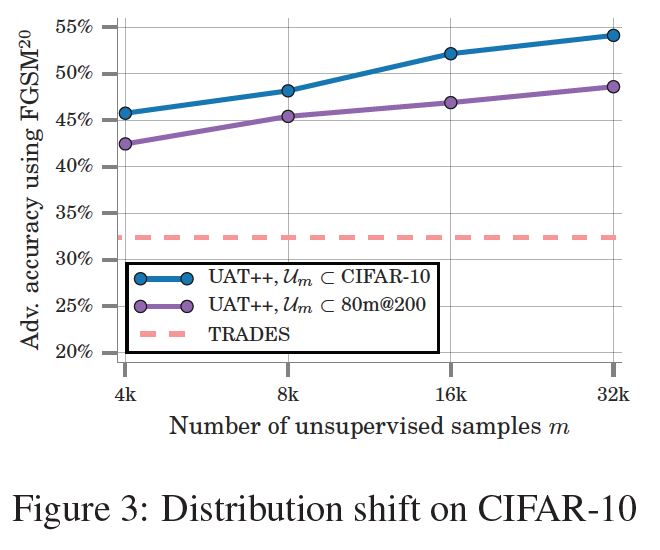
- setup은 앞의 4.1.1과 동일하다.
4.2.2 Large scale regime
- Training set은 80m개의 data에서 CIFAR-10의 여집합을 이용한다.
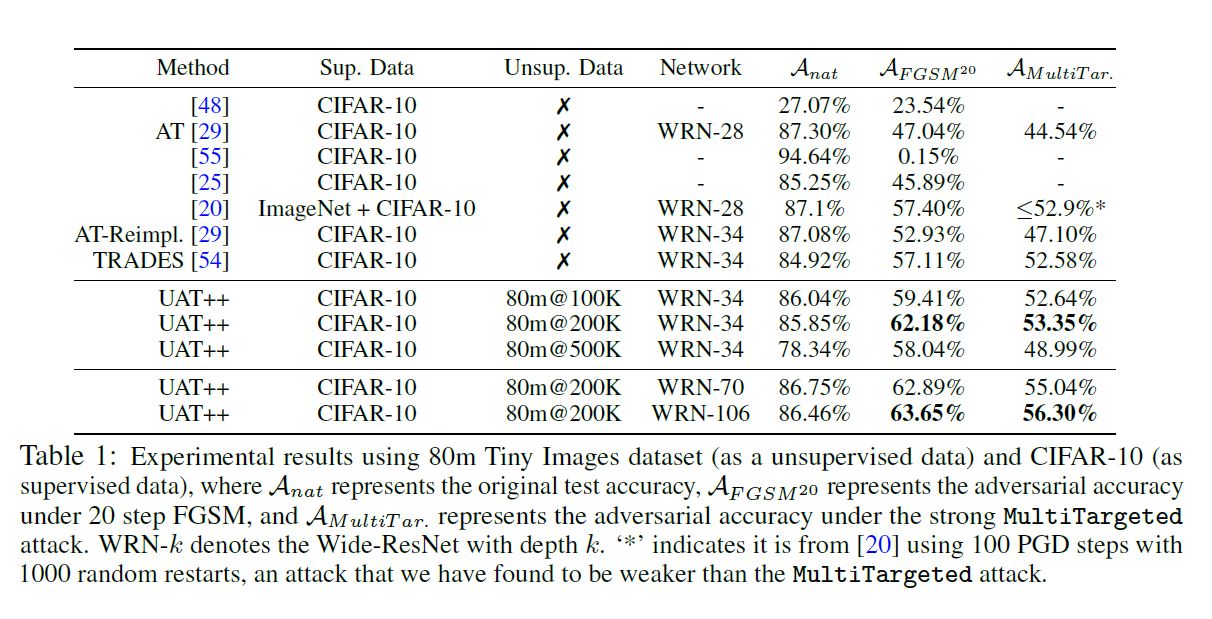
- FGSM attack, Multitargeted attack을 이용한다.
5. Conclusion
- “Label된 data는 일반적으로 생각되어왔던것 만큼 중요하지 않다.”라는 가설을 증명하기 위해서 두가지 간단한 UAT를 이용하였다. 결과적으로 가장 최신의 adversarial robustness만큼 접근할 수 있었다. 더 나아가서 이 방식이 label되지 않은 데이터에도 적용될 수 있다는 것을 보여주었다.
- 이러한 것들이 의료 영역과 같은 robustness가 중요하고 label을 모으는 것이 특히 어려운 영역에 중요해질 것이라 생각한다.
댓글남기기